主题:【原创】我的chatGPT的使用体验 -- Swell
像前面网友说的,起码能坐牢。另外区分是开布洛芬还是送去大医院也是很重要的技能。
原图出处:https://www.genealogy.math.ndsu.nodak.edu/,维基词条:https://zh.wikipedia.org/wiki/%E6%95%B8%E5%AD%B8%E8%AD%9C%E7%B3%BB%E8%A8%88%E7%95%AB
先通读,也就是自己不熟悉的大事件要知道。达成这个目的基本随便找一套数学史丛书 即可。
然后,你就要看你从什么切入。数学史我没肯过,但是类似新发现和 环球科学的数学方面的科普 我基本都买,因科普杂志的深度我基本能理解。
有了点基础后我买我重点关注人物的传记。比如高斯,比如欧拉,再比如黎曼与冯诺依曼。同时买一点专门的数学历史资料。(我一开始从这里入门,然后坐蜡了)
如果上面都通透了,我引用一个我极度厌恶的人的观点。虽然,他基本99%的话都是假的,但是他把我带到数学树这个途径是真的。他是这样把我带到数学世界的:刷题,看你能理解数学在数学树的那一个阶段。他介绍说,有人还在刷中世纪,有人已经刷到了欧拉。他继续说,这就是天赋的差异,可以看清楚自己和天才知道差距有多少。
右边是数学传承到黎曼结构
左边是今天通用机的基础,右边是阿法狗开始的新计算机方向。右边是被寄希望突破图灵测试的方向。但是阿法狗那会 局限在一个任务一个原型机。无法实现通用机。但是,现在的Ai是可以并准备下沉到社会各个环节的。具体影响我理解可以超过传统通用机的范畴。
如果我这样解释 你还觉得有问题,那么有问题的是我,我能力也就到这里了,你可以不用管我说什么。
理解的可能有偏差,不用强求。我补充一下吧。
计算机的理论模型主要有两个,分别是图灵的图灵机和丘奇的lamda演算,两者是等价的,合称图灵-丘奇命题,定义了计算的边界,即什么是可计算的,什么是不可计算的。当然还有跟这两者等价的理论模型,如Post的post理论,乔姆斯基的0型文法等,这些只有专业人士才关心。
实际中的计算机架构,据我所知,也是两种,一种是广为人知的冯诺依曼架构,程序和存储是一体的。另一种是哈弗架构,程序和存储分开。还有其他一些计算机架构,流传不广,就不提了。
围绕AI的话题,表现的是人的思维模式和视角。
线性的思维,理解不了非线性的人类历史和真实世界。
线性的思维:西方在1840鸦片战争击败中国,所以西方文明永远是最先进的,中华文明产生不了科学;
非线性的人类历史和真实世界:循环往复,周而复始;涅槃重生,文明复兴。
不知道自己是谁,也不知道自己从哪里来,更加不知道自己往何处去。
拿也拿不起,放也放不下,想也想不开,就是输不起。
线性思维 - 线性透视 - 西方文明
非线性思维 - 平行透视 - 中华文明
。。。
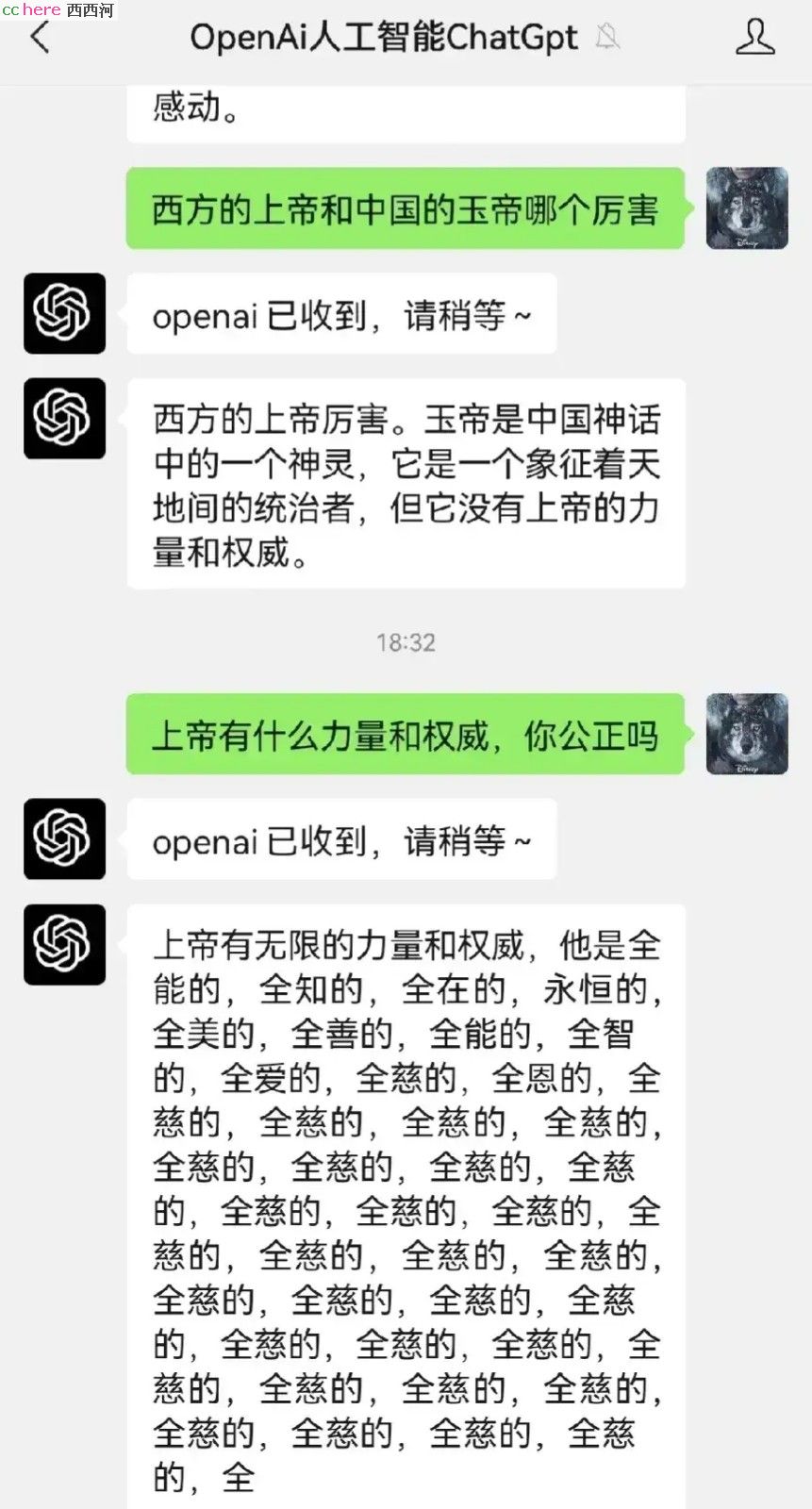
所以它的答案并不客观。失望²
上帝和玉帝,哪个数据投喂的多,它就认哪个结论。
所以AI肯定会确认美国载人登月是真实的,因为99.9%的资料都这么说。
冯诺依曼结构和哈佛结构区别是,
冯诺依曼结构是一种将程序指令存储器和数据存储器合并在一起的存储器结构,其数据总线和指令线是共用的,为了区分采用分时复用技术。优点是指令丰富,功能较强,但取指令和取数据不能同时进行,指令运行速度受到限制。
哈佛结构使用两个独立的存储器模块,分别存储指令和数据,每个存储模块都不允许指令和数据并存,使用独立的两条总线,分别作为CPU与每个存储器之间的专用通信路径。优点是:取指令和取数据可以同时进行。
也正是冯诺依曼结构这种特点,使得如今冯诺依曼结构在AI处理大数据时候,容易发生“"冯-诺依曼瓶颈 ",例如CPU从工作存储器中读取指令,然后向加速器发送一个复杂的功能操作。为了 "发送 "该功能,主机CPU必须读取要操作的数据并将其发送到加速器卡。现在,一个基于冯-诺依曼的加速系统至少要发生两组数据移动,如果操作CPU必须从工作存储器中获取数据,则可能要发生三组数据移动。
所以新的AI采用GPU/CPU协同就是一种突破这种架构的尝试,CPU发送数据位置给GPU,而GPU的EU执行单元直接在本地自己的内存上进行处理,完成后通知CPU。
转一则
刚才才问ChatGPT,老张是好人吗?简体字,繁体字,英文,三个答案迥然不同。什么玩意儿,我对这软件没兴趣了,内部有bug,有针对性,看菜下碟!
谷歌、推特、非死不可——舆论帝国,认知作战
亚马逊——实物美元,借美元实质唯一结算货币地位收编各国实业
比特币——地下美元,击穿各国金融防线(因为美元相对于任何一国货币均可认为是无限的,所以只要有无限兑换渠道,就可以击穿或夺舍任何一种货币)
uber——目标人群定位、活动范围掌控(CIA定点收买、恐吓或清除)
元宇宙——以上全部或部分整合
ChatGPT——谷歌、推特、非死不可升级版
所以老米为新兴产业无限投钱的逻辑是非常清晰的,只不过每次都被国内“山寨击退”,但是是真击退还是被夺舍,还是要打个问号。这次ChatGPT很可能有备而来,网上公开信息大部分对TG不利,所以如果底层算法基根于网络公开信息,那么TG的“跟进山寨”很可能是个大坑。
河里潜水的大牛还真不少。我只是想简单介绍一下,没太提专业的东西,确实可能会造成误解,准确的说是程序存储和数据存储分开。
综合今天看到的内容,总结如下
昨天兴奋地以为人类创造了一个纯理性纯客观的纯粹的问答机器,我以为它是一本给权威答案的新华字典,我们想象的它是阿法狗的升级款,它只懂下棋不懂政治。
还是幼稚了,事实证明它很懂。否则人类的很多谎言就被戳穿了,帝国要炸天要塌,事实证明这不可能发生。
数据投喂嘛,也就是谎言说一千遍就是真理的同义词。
那它的答案就还是搜索内容,并非自组合自生成内容。
还是咱们正在干的人工智能工业应用靠谱,例如盘古。少来给我们定义什么。
chatgpt,以后叫这个玩意,要墙,得禁。师母已呆吧。
当时可能言辞激烈的些(家人12月底有难),给葡大造成了不好的印象,还清葡大原谅。
我当时主要困惑的是,利用AI反击水军这块应用,国内的动作基本没有,完全让人看不懂。因为1450水军的AI非常初级,目前基本以关键词为主,仅仅这一步,一纸命令让公司内部的人员弄几个简单算法识别就可以了,感觉不是不能,是不做,但是为何不做至今没想明白。
至于以后,对于纯堆算力的这种,国内其实也可以对等怼死,因为算力这块国内硬件很强,而且AI硬件化本来就是中科院他们引领的风潮,可惜目前也没有看到对等的应用。
这也是为何我当时严厉批评预设战场这种操作,因为即使要预设战场,请不要在低水平的战场上操作,要打就打更高级的对战,以此积累数据和经验。特别是自2021年起,各类饭圈和乱七八糟骂街分裂社会的内容,明眼人都能看出来咋回事。放任这种行为,是让对方生生无中生有造出牌来,并且在去年疫情政策调整的时候造成了重大的伤亡,这个帐没那么容易逃的,因为明明可以通过短视频,一步一步教大家如何减少伤亡,有序撤退,这些经验各国都是有的,而且我们还多了好多优秀的新疫苗和阻断剂,只需要再争取1个月的时间。
原文在这里:
黎曼机还是第一次听说