- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【原创】什么是RCT--- 送给中间派的您 -- 虽远必诛
家园 【原创】什么是RCT--- 送给中间派的您 世界上最累人的就是同精神病说话,在什么是RCT,什么是SR都不懂就要出来点评Cochrane reviews,无知最勇敢。而且还声称最有力的反击,笑掉大牙了。
送给中间派的您,简单介绍一下什么是RCT。
RCT:randomized controlled trial 随机控制试验,实际上还要加上双盲或者三盲,double/triple blinded 。
1,为什么要做临床试验?要验证是否有效?不论是药物,理疗,护理,还是手术,诊断等等。
在观察的基础上,还要验证,比如说说您看到了喝尿能够长寿,这个是目前的两个孤立的现象,是否两者间有必然联系,还是偶然现象?这个就要做前瞻性的试验 prospective trial,同个人的临床经验的总结不同那个是观察性的,回顾性,observational, retrospective 。
所以观察的东西,不代表就有效,眼见不一定就为实。拿雨伞打狮子的事情经常发生。
因此任何所谓的个人经历,医案,临床经验都不如试验。
试验的目的就是要验证,你拿起雨伞,狮子就倒下这个俩者间的关系。
如果在一定次数内,(sample size)一定情况下,消除其他因素(比如说邻居拿猎枪),每次您都能用雨伞打倒狮子,那么就可以得出雨伞能打倒狮子的结论。哦,同时还要做另外一组,就是不拿雨伞,是否能够打倒狮子,如果也倒了,就不能说是雨伞打倒狮子,可能内就是酥哥转世。
2,为什么要控制试验。因为人是复杂的社会性动物。
很多种因素,自然,不自然,知道,不知道的影响您的健康,影响评估。
还是拿雨伞打狮子的例子,如果您有一个忠心的仆人,看见狮子过来,就开枪,您的出的结论就是,您的雨伞很神气。同皇帝的新装一个道理。
还有人是有思想的动物,做试验的人,和患者都有自己的主意。
比如说您告诉患者这个锻炼方式好,能够如何,如何,他就多练,或者在测试的时候更加用力,那么得出的结果就是锻炼有效。
这个叫hawthorne effect,就是患者自觉不自觉地达到您期望的方向。
典型的例子是,给学生分快慢班,结果,快班的学生成绩就好,慢班的就差。
这并不是因为分快慢班的结果,而是给学生的印象就是,快班的学生就好,成绩就该高。
相反,如果分1,2,3班就没有太大差异。
3,为什么要对照?control group。 因为要比较,您自己说有效没有用,要同目前认可的方式比较,要同没有治疗的方式比较,要同胡乱搞相互比较。
典型的例子,以前说过,就是号脉知男女。
要同B超做比较,两组患者,一组号脉,一组B超,是骡子是马,拉出来,遛遛就知道了。
同时还要同没有诊断,就是瞎猜,比较。
所以应当是一组,号脉,一组,B超,一组,瞎猜。
另外在进行比较的时候要消除一切的影响因素,confounding factors,比如说问话,看面色,看走路等等。
所以这个试验可以是,同一组孕妇。由三波人竞争,在一个完全黑暗的房间。
一组,号脉,一组,B超,一组,瞎猜。
最后的结果,要看两点,一点是正确率,一点是错误率,最后得出号脉是否能够知男女的结论。
您可能说,除去正确就是错的,WRONG, 不光有男女,还有双胞胎,还有阴阳人。
三:安慰剂的问题。以前写过了。链接出处,现在看看安慰剂有什么坏处?你说能止痛就好,这个没错,跳大神,催眠术也能止痛,是否您愿意付钱,同时很大程度上是信则灵,不信则不灵,去看心灵捕手就知道了。对于不信的患者,是否可以不付钱,否则还是同为什么要付钱?
另外就是很多的药物,都或多或少有安慰剂效应。到底谁有效?给谁批准文号,又不给谁?是不是当年老顽童搓泥球给人吃也是药?大赖的洗脚水更有效,是否也可以堂而皇之的上市销售?
所以,屏弃安慰剂效应是医疗中最基本的常识。
这里不仅仅是针对中医,西医也是一样。
最后安慰剂效应,通常对主观指标有效,客观指标无效,临床价值非常有限。
4,RCT的历史有多长?非常短,从第一RCT开始到现在103年。
Fletcher W (1907). Rice and beri-beri: preliminary report on an experiment conducted in the Kuala Lumpur Insane Asylum. Lancet 1:1776-9. 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改William Fletcher 是一位英国的内科医生,在吉隆坡的一个政府部门工作---监狱。
"White rice can be poisonous!" This was the conclusion Christiaan Eijkman declared in 1896 on his return to the Netherlands, after ten years of research in Batavia, Java in the Dutch East Indies (now Jakarta, Indonesia).大约十年前,荷兰的生理学家 Christiaan Eijkman发现一个现象脚气病同吃精食料的关系,认为是精米中有一种毒素,导致了脚气病,还进行了观察性的试验。但是没有结论。但是因为这个他获得了1929年生理学医学炸药奖。
Fletcher 医生利用先天便利--- 犯人做样本。分成两组,一组吃精米,一组吃粗米,结果5周后吃精的得脚气病的多,吃粗米的没有。然后让吃精米得脚气病,进入吃粗米的牢房,脚气病就好了。
这个是典型,随机分组,(犯人没有任何选择余地),安慰剂对照,精米,粗米。单盲试验,犯人没有知情权。
先写到这里,去上班,回来写,医疗试验设计的从临床角度的要点。
通宝推:然后203,daharry,回旋镖,家园 送花得宝 感谢医生为俺们进行科普!
家园 支持 有逻辑的实证。
家园 临床试验特点九 样本数量 sample size
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改样本数量是试验的重要一环,因为太多的数量导致浪费(金钱,生命),太少的样本没有意义,同时对参加试验的人员也是不道德的行为。
因此恰到好处最好。
如何达到恰到好处就要看您对误差的控制如何了。
Type-1 Error (α): This is the false positive rate orprobability of declaring a treatment difference
where none exists. Also known as significance level
or α-level. Usually fixed at α = 5% (two-sided) by
regulatory agencies.
FDA确定的标准是α = 5%。如果您希望试验更有说服力设置α = 1%那就需要更多的样本。也就是99%的可能性实验的结果是从intervention(药物,治疗) 来的。
Type-2 Error (β): This is the false negative rate or
probability of failing to detect a treatment difference
that actually exists. It is also called the β-error and
1 β is known as the power of the study.
通常认定的是β=20%。
Table 1 – typical values for significance level and
5% 1% 0.1%
1.96 2.5758 3.2905
power Significance level Power
80% 85% 90% 95%
0.8416 1.0364 1.2816 1.6449
有很多的样本计算工具,这里介绍一个简单的
m=2*(z(1- a /2)+z(1- b ))*(z(1- a /2)+z(1- b ))/Δ*Δ
比如说,您用两种药物对比,一种已知药物的有效率是40%,您希望您新药物的有效率是50%
Δ=P1-P2/√P1+P2/2*(1-P1+P2/2)=0.201
z (1- a /2) = 1.96
z(1- b ) = 0.8416
所以M=388.5,上进一位到最近的整数 389,两组就是778人。
另外的常用方式是计算变动值同标准差SD之间的关系,比如说血压降低5mmhg是有临床价值,但是正态分布的标准差是10mmhg。
Δ=5/10=0.5,同样
z (1- a /2) = 1.96
z(1- b ) = 0.8416
这样M=84.1,上进一位到最近的整数85,所以总共要170个患者。
这里您看到如果您改动α β的数值会显著的改变对样本的需求量。因此在看文献的时候都要详细地看到底作者把这些数值设定多少。
同时其他的Δ的数值同以前的实验有很多的关系,尤其是pilot study。
所以不同的实验要求不同的Δ数值,直接导致样本数量的差异。
这些同检测标准,检测方法都有一定的关系,也就是说您的检测方法得到认可,才能推到处,监测的结果有明显差异性。
自己声称的没有用的。
家园 临床试验特点八: 测量是临床试验中比较关键的一个环节,谁来测量,测量几次,用什么方法,几个测量者,测量着是否是知道分组情况,跟踪的时间等等都会直接影响试验的质量。
通常最简单的方法是 两点测量,所谓的A-B线。A试验前的基础线 baseline, B试验后的变化。如果两组治疗组 同安慰剂组A1=A2,但是试验后A1〉A2就可以判定,药物有效。
但是实际试验中还有很多因素需要控制。
比如说测量数量,如果疾病有一定的自娱性就至少要测量三次,两次在试验前, A1,A2 间隔一段时间,然后是A3,如果A3=A2〉A1说明治疗没有意义,疾病的自愈性起到了决定性作用。比如说普通感冒,测量第一天,第七天,然后给药,测量第八天,(或者第十四天),第七天=第八,第十天〉第一天,就不能说药物有效。
再有如果疾病是慢性的,无法根治的就要长期跟踪,看看长期效果如何。典型的如糖尿病。
还是A1是基础线,A2 治疗后(比如血糖控制正常),A3 几个月之后,如果A1=A3《A2,就是能说,药物对疾病在短期内有效,长期看没有明显治疗价值。
燕轻笑提出的问题就是这个例子
个人经历,请教一下我参加过一个皮肤病的新药的试验,一种是国产新药,一种是国外的药,不知道自己打的是哪种,打了以后三个月复查,效果很好。
结果一年以后我同一部位又复发了。
问:此复发记录是否对该药的检验结果有无影响?
在试验结论部分要写上,药物治疗观察三个月内效果如何,也就是说结果是有一定条件。
目前如果大家都是玩一个游戏,对疾病的预后不会出现太多的歧义。慢性病说三个月内有效,看的大夫就知道,这个试验是短期。因此在临床中就会有的放矢的使用。
测量人也非常有说道,几个人,水平如何,所谓inter, intra validity 如果试验报告中没有提到几个检测的人,说明试验设计不好,两个是最少,还要写上,之间的差异性。
测量的设备也很重要,不要说你用的就是好的,两种方式被介绍,1 大家公认的基标准,gold standard,比若说空腹血糖对糖尿病,NDI(neck disability index )对颈部疾患,(whaplash,颈椎病之类),MRI 对ACL 损伤,VISA 对髌腱病等。
因为这些都是经过反复试验检查的,业界公认。如果您说,用疼痛VAS来检查 whiplash,不是不可以,但是得出的结论就没有普遍意义,因为疼痛仅仅是NDI其中的一部分,还有很多的功能性指标,比如说提重物,睡觉等等。
另外就是MDC Minimal detective change 最小可测量的变化,就是说有效,无效是否被接受,不是测量者说了算,是其它的用这个测量方法的试验得出的结果。不允许老王卖瓜,自卖自夸。
这个看的比较清楚外链出处
PSFS patient specific functional scale 是临床用的非常多的针对患者功能的问卷,就是让患者写出来至少五个功能障碍,不论是疼痛,活动受限,还是压力,烦躁等等。
然后得出平均值,治疗后在做这个问卷,如果平均分提高2分,说明治疗有效,单个分数增加3分才有效。
如果得出每项都增加一分,看着很美,但是不被接受。
第二种方法是用新的标准,这个也可以,但是谁主张,谁举证。您可以用腋温来验证肩周炎的进展。但是要有足够的证据,证明腋温变化同肩周炎疗效有关。否则就不能被接受。验证一个新的检测方法也是非常难的,要同公认的金标准比较,要看 specificity 和 sensitivity。而且结果要能够被别人重现。
在这个领域不存在所谓的高手,你可以别人不行的。不能被重现就是不存在。可以参看康奈尔大学造假案和舍恩造价案。都是神奇不能被重复然后发现问题。
回到中医的话题,标准可以自己定,但是要研究同目前金标准的关系,不能说公说公有理,婆说婆有理。
另外要别人认可,重复的了。
现在看看所谓的验脉知男女,不论那一点都不能成为标准。当然脉诊,望诊都是一样的。
关于盲对于试验者的影响以前讲过了。最好是用外来的,第三方检测。实在不行,也要完全屏蔽任何知情的可能性,如果不是双盲结果至少没有双盲的有力。通常不能被采信。
注意这里是屏蔽检查者知情,不是治疗者。针灸师可以知道治疗手段,但是不一定是检查者。
最后介绍所罗门四分组试验:
该设计也是只有一种实验处理,随机选择被试和分组;一共4个组,两个实验组,两个控制组;两个实验组中,一个组有前测与后测,一个组只有后测;两个控制组中,也是一个组有前测与后测,另一个组只有后测。在上面的基本模式中第1、2 组是实验组,第3、4组为控制组;第1、3组有前测与后测,第2、4组只有后测。
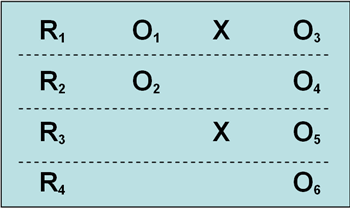 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改这个试验的好处是最大程度上回避了检验着对结果的主观影响。
缺点是分组太多试验费用,周期增加。
总之,看一个试验报告,并不是简简单单看结果,要看很多细节。
这也就是为什么要做SR,作Cochrane reviews因为它们有更多时间,经验关注细节,联系作者,是普通临床医生无法比拟的。也就是说他们是RCT的检查者。
普通医生没有时间,精力去认真检查每一个报告,因为看Cochrane reviews 是临床医生公认的简单,快捷的评估相关领域,目前最有效证据的方法。
这也是,为什么EBM证据标准把cochran reiews 放到第一位的原因。
 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改想批驳cochrane reviews 最好先把,最基础的概念搞清楚在出来说话。
本帖一共被 1 帖 引用 (帖内工具实现)- 复 临床试验特点八:
家园 理论如此,实践如何? 比如监管部门允许发一个新药或者一种新的诊疗方式,是必须有最高级的证据呢,还是次一级的也可以接受?
家园 我们谈论的不是一个东西。 各国药监都要求做RCT才给新药审批的。不存在次一级的问题。
FDA:
The legal requirement for approval is "substantial" evidence of efficacy demonstrated through controlled clinical trials. This standard lies at the heart of the regulatory program for drugs. It means that the clinical experience of doctors, the opinion of experts, or testimonials from patients, even if they have experienced a miraculous recovery, have minimal weight in this process. Data for the submission must come from rigorous clinical trials.The trials are typically conducted in three phases:
* Phase 1: The drug is tested in a few healthy volunteers to determine if it is acutely toxic.
* Phase 2: Various doses of the drug are tried to determine how much to give to patients.
* Phase 3: The drug is typically tested in Double-blind, placebo controlled trials to demonstrate that it works. Sponsors typically confer with FDA prior to starting these trials to determine what data is needed, since these trials often involve hundreds of patients and are very expensive.
* (Phase 4): These are post-approval trials that are sometimes a condition attached by the FDA to the approval.
The legal requirements for safety and efficacy have been interpreted as requiring scientific evidence that the benefits of a drug outweigh the risks and that adequate instructions exist for use, since many drugs are toxic and technically not "safe" in the usual sense.
中国SDA
各期临床试验方案设计要点 1. I期临床试验方案设计要点 I期;临床试验方案应包括依次进行的三部分,即单次给药耐受性试验方案、单次给药药代动力学试验方案、连续给药药代动力学试验方案。 I期临床试验方案应包括以下内容:⑴首页;⑵试验药物简介,包括中文名、国际非专利药名(INN)、结构式、分子式、分子量、理化性质、药理作用与作用机制、临床前药理与毒理研究结果、初步临床试验结果;⑶研究目的;⑷试验样品,包括样品名称、号、制剂规格、制剂制备单位及制备日期、批号、有效期、给药途径、储存条件、样品数量并附药检质量人用合格报告单;⑸受试者选择,包括志愿受试者来源、人选标准、排除标准、入选人数及登记表;⑹筛选前受试者签署知情同意书;⑺工期试验方案、病例报告表(CRFs)及知情同意书应报送医学伦理委员会审批,批准后才能开始I期临床试验⑻试验设计与研究方法(要点见后);⑼观察指标(见后);⑽数据处理与统计分析;⑾总结报告;⑿末页。 1.1 单次给药耐受性试验设计与研究方法要点 ①一般采用无对照开放试验,必要时设安慰剂对照组进行随机双官对照试验。 ②最小初试剂量按Blackwell改良法计算并参考同类药物临床用量进行估算(见李家泰主编《临床药理学》第二版 1998:298)。 ③最大剂量组的确定(相当于或略高于常用临床剂量的高限)。 ④剂量组常设5个单次给药的剂量组,最小与最大剂量之间设3组,剂量与临床接近的组人数8~10人,其余各组每组5~6人。由最小剂量组开始逐组进行试验,在确前一个剂量组安全耐受前提下开始下一个剂量,每人只接受一个剂量,不得在同一受试者中在单决给药耐受性试验时进行剂量递增连续试验。 ⑤方案设计时需对试验药物可能出现的不良反应有充分的认识和估计,方案应包括处理意外的条件与措施。 ⑥与试验方案同时设计好病例报告表(Case Report forms,CRFs)、流程图(Chart)与各项观察指标。 1.2单次给药药代动力学试验设计与研究方法要点 ①剂量选择选择单次给药耐受性试验中全组受试者均能耐受的高、中、低3个剂量,其中,中剂量应与准备进行临床Ⅱ期试验的剂量相同或接近,3个剂量之间应呈等比或等差关系。 ②受试者选择 选择符合入选标准的8~10名健康男性青年志愿者,筛选前签署知情同意书。 ③试验设计采用三向交叉拉丁方设计。全部受试者随机进入3个试验组,每组受试者每次试验时分别接受不同剂量的试验药,3次试验后,每名受试者均按拉丁方设计的顺序接受过高、中、低三个剂量,两次试验间隔均超过5个半衰期,一般间隔7~10天。表 三向交叉拉丁方方案 随机分组 第一次试验剂量 第二次试验剂量 第三次试验剂量 第一组 低 中 高 第二组 中 高 低 第三组 高 低 中 ④生物样本选择适宜的分离测试方法,最常用的方法为高效液相色谱法。应详细写明具体的测试方法、测试条件和所用仪器名称、型号、生产厂与出厂日期。 ⑤药代动力学测定方法的标准化与质控方法 ·精确度(Precision):日内差CV%应<10%,最好<5%。 ·重复性(Reproducibility):日间差CV%应<10%。 ·灵敏度(Sensitivity):①要求能测出3~5个半衰期后的血药浓度,或能检测出1/10Cmax浓度;②确定为灵敏度的最低血药浓度应在血药浓度量效关系的直线范围内,并能达到精确度考核要求。 ·回收率(Recovery):在所测标准曲线浓度范围内药物自生物样品中的回收率应不低于70%。 ·特异性(Specificity):应证明所测药物为原形药。 ·相关系数(Correlation Coefficient):应用两种方法测定时,应求相关系数R值,并作图表示。 ⑥药代动力学测定应按SDA审评要求提供药代动力学参数。 ⑦药代动力学研究总结报告应提供 ·研究设计与研究方法。 ·测试方法、条件及标准化考核结果。 ·每名受试者给药后各时间点血药浓度、尿浓度与尿中累积排出量的均数±标准差,药时曲线图。 ·对所得药代动力学参数进行分析,说明其临床意义,对Ⅱ期临床试验方案提出建议。 1.3 连续给药药代动力学与耐受性试验设计与研究方法要点 ①受试者选择8~10名健康男性青年志愿受试者,筛选前签署知情同意书,各项健康检查观察项目同单次给药耐受性试验。 ②受试者于给药前24小时、给药后24小时、给药后72小时(第四天)及给药7天后(第八天即停药后24小时)进行全部检查,检查项目与观察时间点应符合审评要求(包括国内、国际)。 ③全部受试者试验前1日入住Ⅰ期病房,接受给药前24小时各项检查,晚餐后禁食12小时。试验当天空腹给药,给药后2小时进标准早餐。剂量选用准备进行Ⅱ期试验的剂量,每日1次或2次,间隔12小时,连续给药7天。 2 Ⅱ期临床试验方案设计要求 2.1 Ⅱ期临床试验方案设计需遵守以下基本原则与指导原则 ①《赫尔辛基宣言》 ②我国《新药审批办法》。《新药审批办法》于1985年7月1日发布施行,1998年修订,修订后的《新药审批办法》于1999年3月12日经国家药品监督管理局(SDA)审议批准并于1999年5月1日发布施行。 ③我国GCP指导原则。我国《药品临床试验管理规范》(试行)于1998年3月2日发布施行。1999年SDA组织专家进行修订,修订稿经SDA审议批准后,已发布施行。 ④WHO的GCP指导原则。1993年WHO的GCP指导原则草案广泛征求意见,1993年11月在WHO基本药物应用专家委员会通过,1995年正式发布于WHO刊物中。(The Use of Essential Drugs. Tech Rep Ser No.850, 1995:97) ⑤ICH-GCP指导原则。进行国外一类新药(特别是ICH成员国的一类新药)临床试验时,除执行我国各项指导原则与法规要求外,尚需符合ICH- GCP要求。 ⑥我国《新药(西药)临床研究指导原则》。各类新药临床试验中各项技术要求至少要达到该药临床研究指导原则中规定标准。 2.2 Ⅱ期临床试验方案设计中伦理方面考虑要点 ①临床试验方案设计应遵照执行以下几点。 ·赫尔辛基宣言伦理原则。 ·GCP指导原则。 ·SDA注册要求。 ②临床试验方案设计前应认真评估试验的利益与风险。 ③确保试验设计中充分考虑到受试者的权利、利益、安全与隐私。 ④临床试验方案(Protocol)、病例报告表(CRFs)与受试者知情同意书(Informed Consent Form)均应在试验前经伦理委员会审议批准,并获得批准件。 ⑤治疗起始前需获得每例受试者完全自愿地签署的知情同意书。 ⑥参加试验的医生应时刻负有医疗职责。 ⑦每个参加试验的研究人员应具有合格的资格并经过很好的训练。 ⑧临床试验应建立试验质量控制系统。 2.3 Ⅱ期临床试验方案设计中科技方面考虑要求 ⑴试验方案设计时应充分考虑到GCP指导原则中有关科技方面的规定;应符合《新药临床研究指导原则》中有关类别药物所规定的技术标准;应严格执行 SDA《新药审批办法》中规定的注册要求。 ⑵应规定明确的诊断标准,以及观察疗效与不良反应的技术指标和判定指标为正常或异常的标准。 ⑶Ⅱ期试验必须设对照组进行盲法随机对照试验,常采用双盲随机平行对照试验(Double-Blind, Randomized, Parallel Controlled Clinical Trial)。双盲法试验申办者需提供外观、色香味均需一致的试验药与对照药,并只标明A药B药,试验者与受试者均不知A药与B药何者为试验药。如制备 A、B两药无区别确有困难时,可采用双盲双模拟法(Double-Blind, Double Dummy Technique),即同时制备与A药一致的安慰剂(C),和与B药一致的安慰剂(D),两组病例随机分组,分别服用2种药,一组服A+D,另一组服 B+C,两组之间所服药物的我观与色香味均无区别。 ⑷Ⅱ期临床病例数估计(Assessment of Trial Size)。 ·各期临床试验病例数需符合SDA规定要求,Ⅱ期试验按规定需进行盲法随机对照试验100对,即试验药与对照药各100例共计200例。 ·根据试验需要,按统计学要求估算试验例数。如试验药疗效明显超过对照药时,为获得试验药优于对照药具有统计学显著意义,可按公式求出应该试验的例数。 ⑸病例选择入选标准(Inclusion Criteria)、病例排除标准(Exclusion Criteria)与病例退出标准(Withdrawal Criteria)。根据不同类别的药物特点和试验要求在试验方案中规定明确的标准。 ⑹剂量与给药方法(Dosage and Administration)。 ⑺疗效评价(Assessment of Efficacy)。我国规定疗效采用4级评定标准:痊愈(Cure)、显效(Markedly Improvement)、进步(Improvement)、无效(Failure)。 (痊愈例数+显效例数)/可供评价疗效总例数×100=总有效率(%) ⑻不良反应评价(Evaluation of Adverse Drug Reactions)。 ·每日观察并记录所有不良事件(Adverse Event)。 ·严格执行严重不良事件报告制度。严重不良事件为:死亡、威胁生命、致残或丧失(部分丧失)生活能力、需住院治疗、延长住院时间、导致先天畸形。发现严重不良事悠扬需在24小时内报告申办者与主要研究者,并立即报告伦理委员会与当地药品监督管理部门。 ·不良事件与试验药的关系评定标准表 不良事件与试验药物的关系评定标准 5级评定 7级评定 肯定有关 肯定有关 很可能有关 很可能有关 可能有关 可能有关 可能无关 很可能无关 肯定无关 可能无关 肯定无关无法评定 ⑼病人依从性(Patient Compliance)。门诊病例很难满足依从性要求,试验设计时应尽量减少门诊病例入选比例。对入选门诊病例应采取必要措施以提高其依从性。 ⑽病例报告表(Case Report Forms, CRFs)。病例报告表的设计面与试验方案设计一致,应达到完整、准确、简明、清晰等要求。 ⑾数据处理与统计分析(Data Management and Statistical Analysis)。应在试验设计中考虑好数据处理和统计分析方法,既要符合专业要求也要达到统计学要求。 ⑿总结报告(Final Report)。试验设计时应考虑到总结要求。试验结果比较包括:各种记分、评分的标准;两组病例基础资料比较应无统计学显著差异;各种适应症两组疗效比较;两组病例总有效率比较;具有重要意义的有效性指标两组结果比较;两组不良反应率比较;两组不良反应临床与实验室改变统计分析,等等。 3 Ⅲ期临床试验方案设计要求 ①Ⅲ期临床试验按照SDA在1999年5月1日发布施行的《新药审批办法》中规定应在新药申报生产前完成。在Ⅱ期临床试验之后,紧接着进行Ⅲ期临床试验。 ②Ⅲ期临床试验病例数《新药审批办法》规定,试验组≥300例,未具体规定对照组的例数。可根据试验药适应症多少、病人来源多寡来考虑。单一适应症,一般可考虑试验组100 例、设对照组100例(1:1),试验组另200例不设对照,进行无对照开放试验。有2种以上主要适应症时,可考虑试验组与对照组各200例(1:1),试验组别100例不设对照,进行无对照开放试验。若有条件,试验组300例全部设对照当然最好。若国家药品监督管理局根据品种的具体情况明确规定了对照组的例数要求,则按规定例数进行对照试验。小样本临床试验中试验药与对照药的比例以1:1为宜。 如试验目的为判定试验药是否显著优于对照药,则可按以上2.2.3.2的公式计算病例数。 ③Ⅲ期临床试验中对照试验的设计要求。原则上与Ⅱ期盲法随机对照试验相同,但Ⅲ期临床的对照试验可以设盲也可以不设盲进行随机对照开放试验(Randomized Controlled Open Labeled Clinical Trial)。某些药物类别,如心血管疾病药物往往既有近期试验目的如观察一定试验期内对血压血脂的影响,还有长期的试验目的如比较长期治疗后疾病的死亡率或严重并发症的发生率等,则Ⅱ期临床试验就不单是扩大Ⅱ期试验的病例数,还应根据长期试验的目的要和要求进行详细的设计,并做出周密的安排,才能获得科学的结论。 3.4 Ⅳ期临床试验方案设计要点 ①Ⅳ期临床试验为上市后开放试验,不要求设对照组,但也不排除根据需要对某些适应症或某些试验对象进行小样本随机对照试验。 ②Ⅳ期临床试验病例数按SDA规定,要求>2000例。 ③Ⅳ期临床试验虽为开放试验,但有关病例入选标准、排除标准、退出标准、疗效评价标准、不良反应评价标准、判定疗效与不良反应的各项观察指标等都可参考Ⅱ期临床试验的设计要求。任何的单独病例报道式的,都绝对不可能得到审批的。
我们这里谈的是从临床角度上看。大多数都是已经上市的药物,进行比较,为啥用A不用B。
这就要看证据的级别了。
这也是为什么要做EBM的原因,说服太多,总要有一个标准才好,否则公说公有理,婆说婆有理。到底听谁的。
会EBM的临床医生要至少有两种能力。
1:会critique article, 自己独立能够评估医学文献。
但是这个还有很多的局限性,比如说时间,对文献的资料掌握,很多的文献是要钱的,对文献深度的掌握,您不能每个都联系员是作者,而且人家也未必打理你。
2:要会看证据的级别。不是说cochrane reviews就是圣经,而是人家资料全,深度高,经验丰富,得出的结论比自己做的可靠性好。
但是反过来,如果没有SR,没有cochrane reivews就要自己做,如果SR或者cochrane reviews 的内容同您的患者人群不一致,也需要自己做,比如说,您要给小孩子看,但reviews的是大人小孩都有,或者仅仅是大人,就没有办法作为证据。
但是不论如何,会EBM的临床医生到要至少会评估文献,要自己会写论文。这样才知道文献说的是什么。
至于病例报道,专家意见(不是所谓的专家,是在该研究领域的专家,尤其是临床研究的),患者选择都要低于SR更低于cochrane reviews.
以后有机会还会讲到如何评估SR。
这些都有评分标准的。
家园 临床实验特点7 对照组 control group。
为什么要设置对照组?没有比较就没有明确结果,你说你喝尿长寿,别人不喝尿液也长寿,可能还比你更长,就说明和尿长寿是不对,可能得出喝尿有害的结论。
所有的专家,高手,大师的个人医案,经历都缺乏对照组。
如果没有,就是说你行你就行了,不服不行。
对照有几种?通常用的有四种,
1,安慰剂对照placebo control,就是给形状完全一样的没有任何疗效的任何生理作用的物质。
最长用的是淀粉片。
很多人说中药不能安慰剂对照,因为汤药才是唯一,但是汤药很容易分辨。
这个不是问题,可以做成肠溶胶囊,这样不影响吸收,也不会被患者发现。
除非您认为,中药的有效是汤药中的热水。
还有可以直接下胃管,鼻饲等,给两个一样,封闭,不同明包装。自然就分不清,那个是安慰剂,那个是药物了。
2,药物对照,或者治疗对照。比如说针灸对按摩,这个也可以,但是控制安慰剂效应就比较难。但是药物还是可以做的到的。
3,空白对照,这个厉害了,什么都给看看,到底是安慰效应,还是白费钱。但是比较容易出现伦理问题。
4,自身对照self-control,用于一些长期慢性,罕见的疾病,比如说MND,方法是测量基准线 baseline,A0, 然后给药物或者治疗A1,然后停药,测量B0,然后再给药,测量,再停药,在测量B1。
证明有效的是,A1>A0,B0>A0,B1>B0,B1>A1.
就是给药有疗效,停药下降,但是不会到基准线,再给药,还有疗效。
下次写如何测量。