主题:谈谈大型网站架构的一些关键技术 -- 季侯
家园 谈谈大型网站架构的一些关键技术 最近12306很火,无数人站出来为铁道部指点迷津,提出了无数个解决方案。虽然很多人没做过网站也没写过程序,,,,,
乘罗教主还没空,我也凑个热闹,说说网站架构的一些东东。当然了,纯技术的东东可能没人喜欢,所以我保留随时挖坑不填的权力。
下级预告
一个网站的前生今世
附:
过年忙着抱儿子,都没空写东西,先转一个别人的东东。
据路边社消息,作者是一个taobao的实习生,内容不完全准确,但是能让大家有个整体感受
家园 2 淘宝的背后 一个淘宝实习生写的东东,后生可畏啊!
最近忙着抱孩子做家务,没空写东西,先转个别人的文章,看看大家有兴趣不
本帖一共被 1 帖 引用 (帖内工具实现)- 复 2 淘宝的背后
家园 看了这些,白手起家做网站的童鞋是不是还是洗了睡吧 俺不太确定,以下几方面到底哪些是最恰当的理解:
* 唯一的机会就是有新创意,等大家伙发现你已经起来了。
* 大家都是从一台普通服务器开始的,流量大了就往上叠加呗!
* 要么就是网站做大了以后为了吓唬竞争对手或自我宣传把这些说得神乎其神。
家园 这三条都不全对 * 唯一的机会就是有新创意,等大家伙发现你已经起来了。
理论上是如此,但是基本做不到。
现在业界对新创意还是很敏感的,基本是稍有规模就被发现,然后有实例的抄袭者就来了;如果没被发现,那么风投也不会知道你。
* 大家都是从一台普通服务器开始的,流量大了就往上叠加呗!
的确大家都是从一台服务器开始的,但是如果架构不好的话,就算往上堆机器也没用。因为不同时期不同流量要解决的问题是不一样的。
某个著名b2c网站就是业界的笑话,架构很多年没变了,所以堆了再多的机器性能都没啥提高,稍微搞个活动就崩溃。
* 要么就是网站做大了以后为了吓唬竞争对手或自我宣传把这些说得神乎其神。
技术问题没什么神乎其神的,是真是假,做技术的人还是能辨别出来的。
家园 也不是宣传..不过对于初创的童鞋来说也并不可怕. 水涨船高.再大的水淹不死鸭子.你有多大的用户,就有多大的能力.
- 复 2 淘宝的背后
家园 不错,没想到淘宝数据量居然到了1000万GB 家园 政委,您哪儿来的这些数据啊? 我基本上每天把百度新闻过一遍,也没找到您引用的这些关键数据啊?
- 复 2 淘宝的背后
家园 这个实习生文章写得很好哇,赞一个!
家园 【原创】建设一个靠谱的火车票网上订购系统 谈到大型网站的系统设计,这几天新浪微博里正在热议 12306 网上火车票订票系统,可以拿来作为一个案例,针对实际问题做一番探讨。
昨晚我在新浪博客里写了一篇文章,转帖于此,方便大家阅读。
----------------------------------------------------------------
每到春运,买火车票就成为头痛的事情。今年铁道部开设了网上购票,本来是件惠民的好事儿,但是由于订票网站 http://www.12306.cn,没能快速地处理用户的查询和订单,引起网友的冷嘲热讽。
@王津THU 在微博上替 12306 辩解了几句 [1],立刻成为众矢之的。王津有点冤,首先 12306 系统的确有技术难度,初次亮相,出点洋相,在所难免。其次,王津似乎没有参与 12306 项目,大家骂错了人。
即便王津是项目负责人,大家开骂也不解决问题。今年骂完了,明年是不是接着骂?不如讨论一些有建设性的设计方案,但愿明年春运时,大家能够轻松买到车票。
有评论说,“你们这些建议都是YY,铁道部不会听你的”。
你说了,铁道部不一定会听。但是你不说,它想听也听不到。为自己,为亲友,为老百姓,说总比不说好。
又有评论说,你们这些设计,“都是大路货,没技术含量”。
12306 网站不是研究项目,而是旨在解决实际问题。此类系统的设计原则,实效是首要目标,创新是次要目标。
@简悦云风 提了个建议,分时出票,均摊流量。“卖票这种事情,整个需求量(总出票数)摆在那里在。把峰值请求压下来在时间轴上(前后要卖几百小时呢)平摊,业务量就那么点。网站被峰值请求冲挂了,只能是因为简单的问题都没处理好”[2]。
这个办法的确没有什么技术含量,但是很明快很实用,所以是值得推崇的好办法好思路。
说实话,像 12306 这样受众广大的系统,能不创新,尽量别创新。因为创新是有风险的,在 12306 网站玩创新,你是不是把上亿着急回家过年的老百姓,当成实验小白鼠了?
创新主要是学界的活儿。学界强调另辟蹊径,即便新路不如老路好走,但是或许在某某情况下,新路的办法有一定优势。如果是这样,新路仍然有存在的价值。
务虚完毕,下面务实。
一。找到核心问题。
1月12日,拙作“建设一个靠谱的火车票网上订购系统”发表后[3],收到不少同行的反馈。归纳一下,主要有两类评论,
1.“真正的瓶颈,一般会出在数据库上,怎么解决数据的问题,才是核心”。
2.“如果大量的黄牛阻塞队列或者被DDOS攻击的情况下,普通用户会等到崩溃”。
也就是说,支付与登录是 12306 系统的两大短板。
@FireCoder 著文分析 12306 的用户体验和系统瓶颈,印证了上述两个问题。
“最难的两关是登陆和支付,这也是用户体验最糟糕的两步。登陆是最难闯的一关,验证码验证码验证码...,每次尝试等待若干时间,然后总是一个系统繁忙。这是令人着急和上火的一步。支付则是悲催的一步,订单到手,接着在 45 分钟内超时自动取消”[4]。
官方新闻报导,也证实了这两个问题很突出。
“今年购买火车票最大亮点是,可以登录 www.12306.cn 中国铁路客户服务中心,在网上订票。最新统计显示,7天内,12306网站访问用户已占全球互联网用户的 0.902%,每天点击量高达 10 亿人次。12306 网站的带宽已经从最初的400兆扩充到了1.5G,但是每天 10 亿次的点击量,仍然弥补不了网上登录和支付的短版。据了解,12306 网站正在进行后台调试,争取让订票和网上支付系统分开运行,互不交叉,避免拥堵,让整个订票支付流程更加顺畅”[5]。
二。单机与分布式。
有人问,12306 订票系统,为什么不用现成的 IBM z/TPF?
@周洪波-TSP 老师回复,“z/TPF目前仍然是集中式交易处理量最大的,不过如果每张票都要经过 TPF 做唯一性 TP 确认,z/TPF 也是远远不能达到中国铁路处理量要求,需要分布式处理和缓存(队列)技术来分散压力”[6]。
赞同周老师的观点。好汉难敌四虎,再彪悍的武士,也抵挡不住千军万马的围攻。对于中国春运这样的流量冲击,再牛的单机终归会有容量上限,所以单机基本不靠谱。
靠谱的办法,是分布式。分布式需要解决的问题,是如何切割。切割流程,切割数据。
三。横向切割流程。
拙文 [3] 讨论了把 12306 系统,按登录、查询、订票三类业务,切割成三种流程。其中查询业务,又可以再切割成三种,查询车次时间表、查询某车次余票、查询某用户订购了哪些车票。
为什么要不厌其烦地切割流程?因为不同流程的环节构成不同,不同流程用到的数据也不一样,有些是静态数据,例如车次时间表,有些是动态数据,例如余票和乘客订购的车次座位。分而治之,有利于优化效率,也有利于让系统更皮实,更容易维护。
静态数据,更新少,尽可能存放在缓存(Cache)里,读起来快,而且不给数据库添麻烦。例如车次路线和时间表查询,就应该这样处理。
只有动态数据,才必须存放在数据库中。动态数据在数据库中,存放的方式是表。例如,查询余票与订票,就必须这样处理。
四。切割数据。
在 12306 系统中,最关键的数据,是各个车次各个座位的订购状态。存放这些数据的数据格式,是订票表。
最简单的订票的表设计,或许是设置若干列(车次,日期,座位,路段1,...路段N)。例如高铁 G19,从北京始发,途径济南和南京,终点是上海,共三个路段。乘客甲,订购某日G19某座位,从北京始发,途径济南,到南京下车。乘客乙也订购了同日同 车次同座位,但是从南京上车,到上海下车。那么这张表中,就会有一行,(G19,X日,Y座位,乘客甲ID,乘客甲ID,乘客乙ID)。
如果把全国所有日期的所有车次,全部集中在一个数据库实例的同一张表中,那么势必造成数据库的拥塞。所以,必须对表做切割。
@李思Samuel 建议横向切,也就是按行切,“假定现在有100张北京到上海的车票可售,如果有 10 个卫星数据库,那么在未来1秒内,每个卫星数据库各有 10 张票可售。1 秒以后,各卫星数据库向中心数据库提交本地余票量,并由中心数据库重新分配”[7]。
这个办法的确可以达到减少中心数据库负载的目的。但是顾虑是卫星数据库,必须频繁地与中心数据库同步(李思建议每一秒同步一次)。同步不仅导致内网中的数据流量加大,另外,同步需要上锁。分布式锁机制相当复杂,也容易出故障。实际运行中,搞不好会出乱子。
我们的办法是纵向切,根据不同车次,以及同一个车次的不同日期,切成若干表,放进多个数据库中去。这样,每张表只有(座位,经停站1,...经停站N)几列。假如每趟火车的载客人数不超过 5000 人,那么每张表的行数也不会超过 5000 行。
同一个车次,不同日期,分别有一张表。这样做的好处是,可以方便地实现分时出票。假如提前十天出票,今天是1月16日,那么在G19车次的数据库中,存放着 1月16日到1月26日的 10 张表,今晚打烊期间,数据库清除今天的表,并转移到备份数据库中,作为历史记录。同时增添1月27日的表。明天一早开门营业时,乘客就可以预定1月27日的车票了。
把不同车次的表,分别存放在不同的数据库中去,可以有效降低在每个数据库外面,用户排队等待的时间,同时也避免了同步和上锁的麻烦。
另外,假如每趟火车的座位不超过 5000 个,每趟火车沿线停靠的车站不超过 50 个,那么每个车次数据库外面,排队订票的队列长度,不必超过 50 x 5000 = 250,000。理由是,火车上每个座位,最多被 50 位乘客轮流坐,这种极端情况,出现在每位乘客只坐一站。
五。订票流程。
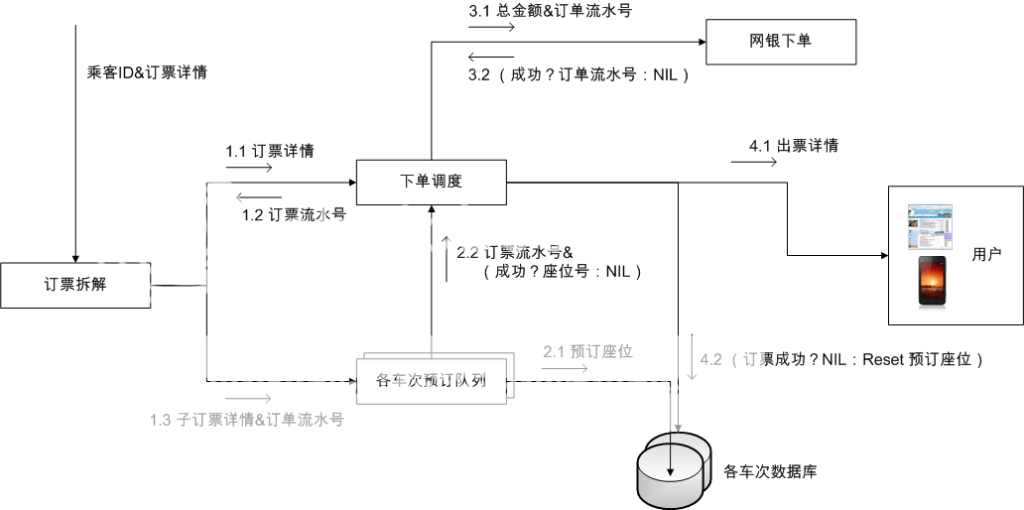 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改图一。订票流程的异步的事件驱动的服务协作模式。
Courtesy http://i879.photobucket.com/albums/ab351/kan_deng/12306-2.png
图一描述了订票的内部流程。例如有乘客想订两张联票,G11从北京到南京,然后D3068从南京到合肥。他从查询页面看到这两趟列车有余票,于是他点击订票。
“订票拆解”服务收到他的订票请求后,先通知“下单调度”服务,跟踪和处理该订单的后续工作,参见图中1.1和1.2。然后“订票拆解”服务分别向G11和D3068两个车次的预订队列,插入请求,分别预订两个座位,参见1.3。
G11和D3068两个车次的订票请求,在各自的预订队列中排队等待。排队结束后,G11和D3068的“预订队列”服务,分别查询各自的数据库,是否还剩余两个座位,参见2.1。
G11车次数据库收到指令后,查询订票表中,是否有两行(对应两个座位),从北京到南京途经的各个路段,对应的列的值,是否都是空。如果有,把这些值改写为订单中的乘客ID。
如果预订成功,G11车次“预订队列”服务,把订单号以及预订的座位号等等,发送给“下单调度”服务。如果没有余票,预订的座位号为空。参见2.2。
“下单调度”服务,会先后收到G11和D3068两个“预订队列”服务,发来的预订信息。只有G11和D3068都预订成功,“下单调度”服务才会指挥网站前端,显示网银下单网页,参见3.1和3.2。
弹出网银下单网页后,如果在 45 分钟内,“下单调度”服务收到网银的回执,汇款到账,那么“下单调度”服务就通知用户,订票成功,以及座位号,参见4.1。如果没有及时收到汇款,“下单 调度”服务就给车次数据库发指令,让它们把预订座位相应的数据,逐一清零,参见4.2。
六。纵向切割流程。
前文中谈到流程切割,主要是按照业务类型切割,是横向切割。对于某一个业务流程,例如订票流程,还可以根据不同环节,做纵向切割。
图一描述了几个服务,分别是“订票拆解”、“下单调度”、“预订队列”、和“网银下单”。之所以是“服务”,而不是模块,是因为这些业务逻辑,各自运行在相互独立的线程上,甚至不同机器上。
在 没有任务时,这些服务的线程处于等待状态。一旦接收到任务,线程被激活。所以,订票系统是异步的(Asynchronous)事件驱动的(Event- driven)的系统架构[8]。这种系统架构,在当下被称作,面向服务的系统架构(Service-Oriented Architecture,SOA)。
之所以采用面向服务的系统架构,最主要的动机是方便扩展吞吐量。
例如在图一中,“下单调度”是一个枢纽,如果流量压力太大,单个机器承受不住怎么办?采用了上述设计,只要加机器就行了,方便,有效,皮实。
七。登录流程。
除了支付是短板以外,登录也是突出问题,尤其是大量用户不断刷屏,导致登录请求虚高。
应对登录洪峰的办法,说来简单,可以放置一大排 Web Servers。每个 Web Server 只做非常简单的工作,读用户请求的前几个 Bytes,根据请求的业务类型,迅速把用户请求扔给下家,例如查询队列。
Web Server 不甄别用户是否在刷屏,它来者不拒,把用户请求(也许是刷屏的重复请求),扔给业务排队队列。队列先查询用户ID是否已经出现在队列中,如果是,那么就是刷屏,不予理睬。只有当用户ID是新鲜的,队列才把用户请求,插入队尾。
这个办法不难,但是经受住了实践考验。
例如2009年1月20日,奥巴马就任美国总统,并发表演说。奥巴马就职典礼期间,Twitter 网站每秒钟收到 350 条新短信,这个流量洪峰维持了大约 5 分钟。根据统计,平均每个 Twitter 用户被其他 120 人关注,也就是说,每秒 350 条短信,平均每条都要发送 120 次。这意味着,
在这持续 5 分钟的洪峰时刻,Twitter 网站每秒钟需要发送 350 x 120 = 42,000 条短信。
Twitter 应对洪峰流量的办法,与我们的设计相似,参见拙作“解剖 Twitter,4 ”[9]。
有观点质疑,“Twitter 业务没有交易, 2 Phase Commit, Rollback 等概念”,所以 Twitter 的做法,未必能沿用到 12306 网站中来 [6]。
这个问题问得好,但是交易、二次确认、回放等等环节,都出现在 12306 系统的后续业务流程中,尤其是订票流程中,而登录发生在前端。
我们设计的出发点,是前端迅速接纳,但是后端推迟服务,一言以蔽之,通过增加前端 Web Servers 机器数量来蓄洪。
又有观点质疑,通过蓄洪的办法,Twitter 每秒能处理 42,000 条短信,但是 12306 面对的洪峰流量远远高过这个数量。增加更多前端 Web Servers 机器,是否能如愿地抵抗更大的洪峰呢?
每逢“超级碗 SuperBowl”橄榄球赛,Twitter 的流量就大涨。根据统计,在 SuperBowl 比赛时段内,每分钟 Twitter 的流量,与当日平均流量相比,平均高出40%。在比赛最激烈时,更高达150%以上。
面对排山倒海的洪峰流量,Twitter 还是以不变应万变,通过增加服务器的办法来蓄洪抗洪。更确切地说,Twitter 临时借用第三方的服务器来蓄洪,而且根据实时流量,动态地调整借用服务器的数量 [10]。
值得注意的是,Twitter 把借来的服务器,主要用于前端,增加 Apache Web Servers 的数量。而不是扩充后端,以便加快推送等等业务的处理速度。
这一细节,进一步证实 Twitter 的抗洪措施,与我们的相似。强化蓄洪能力,而不必过份担心泄洪能力。
Reference,
[1] “海量事务高速处理系统”是一种非常特别的系统,恳请大家不臆测不轻视类似 12306 系统的难度。
http://weibo.com/2484714107/y0i3b53dd
[2] @简悦云风 的微博
http://weibo.com/deepcold
[3] 建设一个靠谱的火车票网上订购系统
http://blog.sina.com.cn/s/blog_46d0a3930100yc6x.html
[4] 12306 的问题
http://blog.csdn.net/firecoder/article/details/7197959
[5] 铁道部订票网站或分开运行订票与支付系统
http://news.qq.com/a/20120116/000024.htm
[6] @周洪波-TSP 的微博
http://weibo.com/iotcloud
[7] @李思Samuel 的微博
http://weibo.com/u/1400321871
[8] SEDA: An Architecture for Well-Conditioned,Scalable Internet Services
http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf
[9] 解剖 Twitter,4 抗洪需要隔离
http://blog.sina.com.cn/s/blog_46d0a3930100fd5c.html
[10] 解剖 Twitter,6 流量洪峰与云计算
http://blog.sina.com.cn/s/blog_46d0a3930100fgin.html
关键词(Tags): #12306 网上火车票订票系统, 通宝推:然后203,新手爱学习,曾自洲,李根,家园 不赞同,我觉得你钻牛角尖了 12306首页都打不开,其实就一个原因就是页面太花俏了。要是我设计,就像谷歌一样,首页只有两个输入框——出发地和目的地。
另外,推特42000流量绝对要小于12306的负荷。公开报道是最高单日10亿,平均下来也要每秒1万多。但是实际上显然是非常不平均的,峰值至少是平均值的10倍,也就是推特的2倍多。
你的思路理主要是分数据,来减轻服务器的负荷,但是我觉得最好还是分人。
下面说说我的想法:
指导思想就是购票流程上的每一步,都把订票人分散成几组前往不同的下一步。换句话说,最好的学习榜样是谷歌。
第一步,首页,只有输入始发站和终点站的两个。输入了以后,根据始发站的不同,把订票人分流给若干下级设备分别处理。我觉得比较合理的分法是按铁路局来分,一分18,十亿就分成了18个6千万。这一步只需要查询始发站属于哪个路局,就一个查询,数据库压力很小。这一步如果害怕ddos攻击,可以加验证码。
第二步,根据上级设备送来的目的地信息,结合已知的运行图,给出若干个乘车方案。方案排序按照直达优先,尽量少换车来排序。一次给出5个方案也就足够了。这5个方案的形成是根据铁路运行图来设计的,所以不是随时变化的,而是基本固定的,只有新增临客才有变动。所以这些个方案很多都可以预先生成。算下来,压力也不大。这样6千万就分成5个一千二百万了。
第三步,输入乘车时间段。这个时段应该是如干日的一个比较大的范围,这个范围最大是从订票时一直到当前可售的最晚的车票(15日后?)选好了这个时间范围,再根据选定的乘车方案,分到下级系统处理。
第四步,输入要定的票数,(1-5张?),然后登记身份证号,付费。其中默认第一个输入的身份证号是用户账号,用户自设密码,以及联系方式等。
第五步,付费完成后,生成订单。到这里网站的任务就完成了,生成了订单之后就和电话订票,窗口订票一样进入铁路内部的订票系统了。从今年的情况看,这个核心系统还是顶得住的。
第六步,订票如果成功,则记录这个账户,保存相关数据,如果订票不成功,全款退回,重头再来,删除账户。
第七步,深夜,全网核查数据库,有同身份证下大量定票的,全删,退款。有身份证号在公安部通缉名单上的,赶紧通知。有已知是记者,官员,黑社会,军人的,打个折。
这么设计的目的,首先通过层层分流,避免出现瓶颈,其次把票务数据查询往后推,只对交易成功的客户提供查询,减少主系统的负荷。
最后,我觉得单日10亿太夸张了,很可能确实有ddos攻击在里面捣乱。
通宝推:迷途笨狼,家园 意大利铁路网 意大利铁路网 www.trenitalia.com
说实话 这个网站做的还是不错的 经常出各种打折票(提前2周以上预订) 虽然有时候也出Bug和各种幺蛾子
不过考虑到意大利的人口只有6000万 估计网站压力不会很大 不知道有没有参考价值
关键词(Tags): #意大利铁路 火车票预订,家园 真的有这么难吗? 先给邓老大花上,再提点不同看法。
订票系统中登陆,火车线路查询cache的做法大家都有真知灼见。俺就不添足了。 就数据库的tranaction核心探讨一下。
新闻中说火车春运3亿人次。假设春运订票为两星期,那么系统在两星期卖3亿张票。假设系统每天工作12小时。那每秒钟卖票大概500张。是个大数目,但绝对不是前所未有的。
正如邓老大文中引述的。解决方案之一是数据分割,每天每车次做一个table。整个春运订票大概要几百个tables。 每个table有各自的物理存储的空间。把每秒钟500张分散在几百个table里。每个table每秒的transaction峰值也就10-20个。达到这个目标不难。
更直接解决方案是用full ACID in-memory DB。不用做数据分割。所有的春运火车座位都放在内存里,也不过1-200 GB的空间。in-memory DB 对付每秒钟500张票是小菜一碟。 RDBMS的鼻祖老大Stonebraker现在做的VoltDB号称每秒过万的transactions on commodity hardware.
付费是个异步处理,除了credit card authorization,完全可以离线处理。用户不用在线等待。
退一万步,从项目管理来说,铁道部也有大问题。系统上线,有没有作过performance and throughput 测试? 测试通过的标准是什么?
- 复 真的有这么难吗?
家园 这个没做好主要原因还应该是并发量高后死锁/锁定超时太多 了,单纯看TPS没有什么意义的。
它内系统按我了解是跑在JBOSS上面的,听说REDHAT做的支持。这种政治主导项目从来都是要求赶工期的,REDHAT这样的公司到了中国也得服从政治。
家园 前帖没说得很清 主要的意思是系统core transaction的并发量并不是个天文数字。在此要求下有很多方法可解决数据库锁定的问题。
订票系统是要保证核心的transaction consistency。其总数据量与twitter, baidu, facebook不是一个量级。而twitter等强调的是海量数据和系统的availability, consistency的要求不高。 订票系统不用采取复杂的数据分割等big data技术也可解决问题。这是我与老邓看法不同的地方。
如果铁道部还有刘跨越站车头的精神,这些问题是在上线前就会发现解决。这是技术外的话题,扯远了 。。。