- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:寰球同此凉热 -- 本嘉明
“武汉病毒”或许是经过人工修改的,目前有两个疑点。
第一个,哈佛等学校的学者已经指出了:多出1378对非天然的碱基对。
第二个,印度研究人员指出的所谓“S蛋白接入了艾滋病毒的DNA”,后来印度作者把文章撤回了。
《文学城》网站(这个网站是台湾裔美国人在美国运营的)有位博主 “马可安”解释了这两点,我把他的博文简化一下,捋一遍。我本人不是学这个专业的,不敢说对错。
首先,在海外的朋友,可以用 https://www.ncbi.nlm.nih.gov/nuccore/MN908947 来查询各种病毒的蛋白质和核酸序列数据,这个MN908947 就是武汉肺炎病毒的编号。
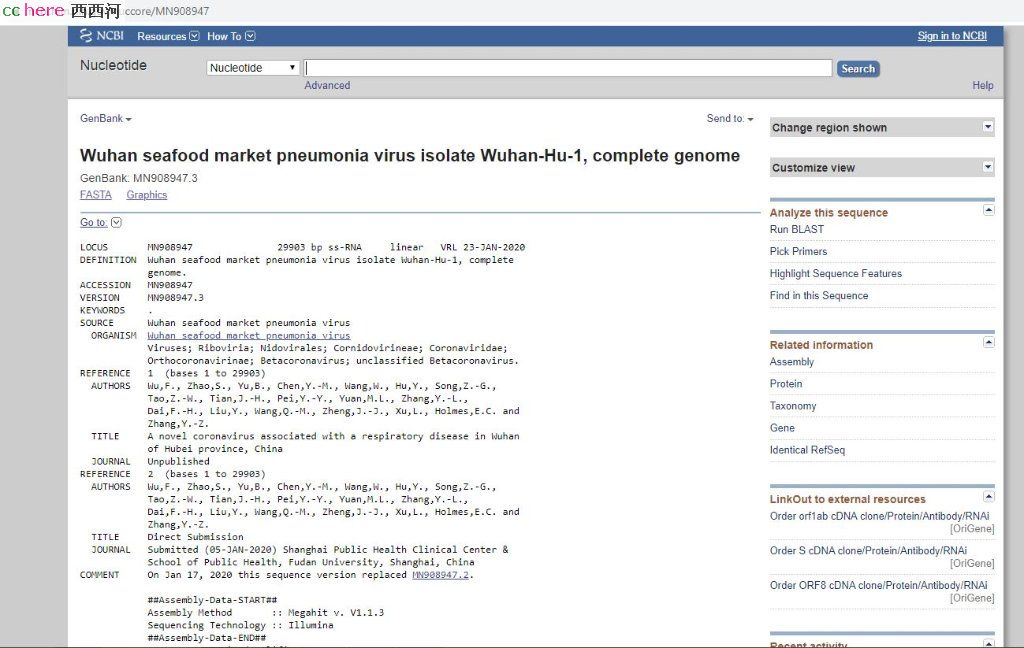
武汉肺炎病毒,与一种 “舟山蝙蝠冠状病毒“(bat-SL-CoVZC45:MG772933),最为接近。这个病毒的核酸序列数据是于2018年1月5日,由南京军事医学院提交到这个国际数据库的。
武汉病毒和舟山病毒,大约有89.12%相似度;而武汉病毒和2003年的非典病毒,则仅有82.34%的近似度。可是最令人惊异的是,武汉和舟山,这两者的E蛋白完全相符,各自有75个相同的氨基酸。
假如单独拿出S蛋白比较,武汉病毒和舟山病毒仅有81%的相似度。而且中间有四小段插入片段,是武汉病毒的S蛋白独有,舟山病毒S蛋白没有的。这4个插入,就是印度学者质疑的人工插入物。
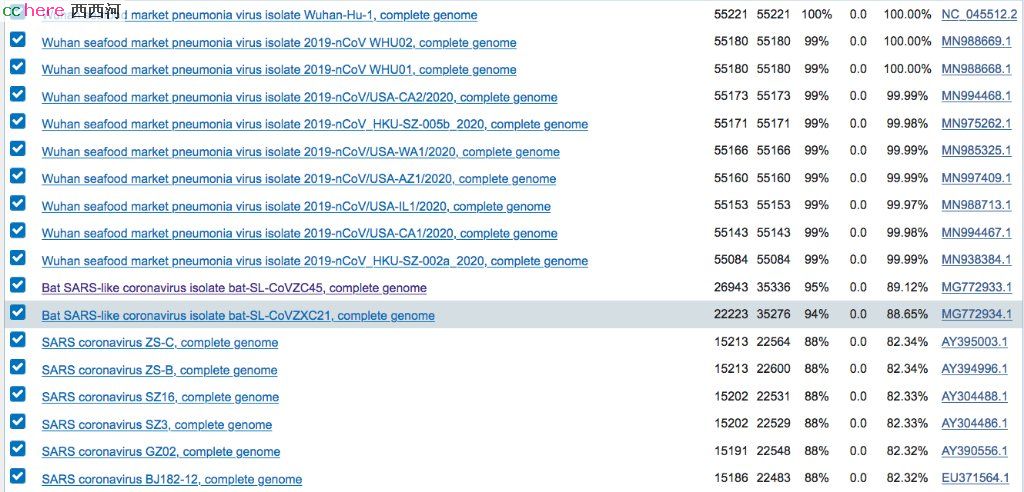
比较武汉病毒和舟山病毒的核酸序列,发现有一大段是舟山病毒没有而武汉病毒被插进去的(21697-23074,长度1378个碱基对)。

上图:红色部分,就是武汉病毒里那多出来的1378长度。
从业学者搜寻比对不同病毒的蛋白质和核酸序列,可以用一个叫“BLAST”的网上工具https://blast.ncbi.nlm.nih.gov/Blast.cgi ,可以在蛋白质或核酸的页面右侧点击Run Blast。运行BLAST的时候,在空框输入具体搜寻的部位数据。
用BLAST搜索这段1378长度的插入核酸,找不到天然类似的来源。可是它会找到一个匹配对象,就是中国科学家在1980年代做的pShuttle-SN,核酸编号为AY862402。
这些结果表明,“武汉病毒”,有一点可能,是以 “舟山病毒”为素材,人工插入一段1378长度的核酸而合成的。
再说说“云南蝙蝠病毒”是怎么回事。这个云南蝙蝠病毒据称是2013年被石正丽团队采集到的,编号MN996532。它和武汉病毒相似度96%,和舟山病毒的相似度仅89%,尤其是它的S蛋白,可以解释武汉病毒里S蛋白的那四个可疑插入物是自然形成,不是人工产物。可是最大的问题是,它是印度科学家即将发表论文声称武汉病毒S蛋白含有艾滋病毒插入物(就是这4个插入物)之前,由武汉病毒研究所在2020年1月27日火速递交的数据,随后印度方面就撤稿了。武汉所递交的时间点有点不同寻常。
最后,马可安从微生物演化树的角度分析:

上图里,多数分叉都可以几乎100%溯源,知道蛋白或核酸的序列来自哪个自然界的祖先,可是武汉病毒分叉的溯源率仅76%,有24%的东西讲不清楚血统。
她的团队是出于“寻找压制非典病毒,预防非典东山再起”的目的,而开始这些研究的。这也是她敢于拿到国际上大大方方交流的原因。虽然她在2015年那篇PAPER,确实引起一些外国学者的不安(她找到一个损伤人类肺功能,而现存所有疫苗都不能抵抗的方法),但那个PAPER是中美合作的结晶,G2出世,谁与争锋?
这个成果,就是一个中美一起握在手里的“恐怖平衡”,假如当年萨达姆有,撒到55万联军头上,大不了伊拉克人民跟着同归于尽,那第一次海湾战争的历史进程就彻底逆转了。
所以即便2015年这个成果是“邪恶”的,其实也保障了世界和平,使得美军不敢来犯。因为人性之恶,只能用实力去压住。
何德何才。
- 待认可未通过。偏要看
如果你贴的这些是真的,那么说明国际势力的主流已经早就在合作,不管是邪恶或者是其他,除了保障世界和平,间接地也是在实现人类命运共同体!
石正丽在2015年11月9日在自然医学上发表文章,修改后的冠状病毒,具体的基因编码,到现在都没有公布?
我感觉是这样的,石正丽修改了冠状病毒,并且将病毒提供给了美国人。
武汉2019-nCoV病毒最初爆发的时候,石正丽以为是病毒所的病毒泄露(试验的野生动物被当成野味卖到了海鲜市场)。
中国疾控中心来了,跟石正丽沟通,1.0版的病毒是不会人传人的。
中国疾控中心受石正丽诱导,为了帮病毒所捂盖子,做出了不会人传人的决定。
但是,实际上,2019-nCoV是石正丽修冠状病毒1.0基础上的升级版,是2.0病毒,这个病毒传染性和危害性更大。
石正丽和CDC 为了掩盖真相,在病毒大规模扩散的情况下,也没有勇气讲出真相。
但两个病毒应该都有人传人的能力,其实一切呼吸道病毒都有人传人的能力,不然病毒不要活活困死在一个个体里面啊?
疾控中心绝对是替领导背锅。
不过,人传人的能力不同病毒是不同的,下呼吸道疾病一般传染能力不强是真的,疾控中心大概也没有想到这个病毒扩散能力这么强,这个锅有点大,背不动。
这个是bootstrapping 的值,是说这个进化分支的可能性有76%,也就是说你把这些标红的物种放到这个位置的可靠性是76%。
另外,文章也说了舟山和新冠病毒有89相似,也就是有大概3000个不同,你觉得这三千个不同里有1378是一个蛋白里的插入片段的可能性有多大?
我们也做了多序列比对,用了很多病毒,没有发现这么大的插入片段。
另外和新冠病毒最近的不是舟山,而是云南蝙蝠,相似度96%,就是说有1200个不同,那么这1378应该在哪里丢失呢?
如果真能这么干,那说明病毒所管理混乱,出现了纰漏。但是目前也没有管理混乱的证据。只是有人发文说病毒所的所长王延轶是靠裙带关系上位,她老公舒红兵是中科院院士。
但靠这两点也无法证明病毒所管理混乱。
先花,几点讨论供商榷。
1)武汉病毒和舟山病毒的差异
根据你引用帖子里的方法,我先在NCBI对武汉肺炎病毒(MN908947) 进行了BLAST对比,现在除了其他武汉病毒的株系(100%),排名靠前的是舟山蝙蝠冠状病毒(MG772933和MG772934, 89%),和各种SARS病毒株系(82%)。
进一步将武汉肺炎病毒(MN908947,29903个碱基对)和舟山蝙蝠冠状病毒(MG772933,29802个碱基对)进行比对,二者之间有约1300多个碱基对的差异。这个差异不是武汉病毒比舟山病毒多了一个片段(从两个病毒接近的全基因组长度也能看出不存在直接的大片段插入),而是两个病毒的这1300多个碱基对区域的核酸序列非常的不同,不能像基因组的其他区域那样同源比对在一起。
这1300多个碱基对对应于武汉病毒中是在病毒棘突蛋白(spike)的编码区(58-513位氨基酸),当我们把武汉病毒和舟山病毒的spike蛋白序列进行比对的时候,二者的序列一致性有81%。下图只截取了前560位氨基酸序列的比对结果

当我们比较编码二者spike蛋白的核酸序列时,同源比对的匹配区是从约第1540个碱基对开始,也即前面约1540碱基对的核酸序列(对应于前513个氨基酸的蛋白序列)同源性差,但蛋白序列差别相对小。在生物体中,由核酸(DNA和RNA)编码蛋白质序列,每三位连续的核苷酸序列(三联体密码子)编码20种氨基酸中的一种,或终止密码子。所以四种核苷酸组成的三联体密码子共有64种(4x4x4),对应于20种氨基酸和三个终止子,显然会出现多个三联体密码子编码同一个氨基酸的情况,即三联体密码子的简并性。在不同的物种之间,编码同一个氨基酸的各个三联体密码子的频率会有所不同,即三联体密码子的偏好性。在武汉病毒和舟山病毒序列的对比中,差异显著的核酸序列(前1540碱基对)和具有同源性的蛋白序列(前513位氨基酸)很大程度上是密码子偏好性造成的。类似地,你举的两个病毒中E蛋白的例子,二者的蛋白序列完全一致(75/75),而核酸序列略有差异(222/225),也是由于偏好性造成的。
蛋白质作为多数细胞生化过程的执行者,其结构和功能由氨基酸序列决定,具有相似序列的蛋白质往往具有类似的结构和功能。
2) “插入片段”与匹配对象AY862402
对“插入片段”与AY862402进行蛋白序列,二者序列一致性为61%(如下图),低于舟山病毒(对比1)中所示的舟山spike蛋白)。这个AY862402序列是2004年12月21日提交,文章发表于Virus Res. 112 (1-2), 24-31 (2005),其中提及了载体的内容和构建目的:
“我们构建了包含N端截短的SARS-CoV Spike(萨斯病毒棘突蛋白S)基因(45-1469碱基对,命名为Ad-S(N))的 重组腺病毒,它编码了截短的棘突蛋白S(490个氨基酸残基,是672个氨基酸的S1亚基的一部分)。”
所以这个片段的来源是SARS病毒,不是人工合成的。
3) S蛋白的插入片段
印度文章的主要观点是武汉病毒的棘突蛋白S具有4个SARS没有的片段,位于约80、150、260和685位,如下图

而当我们把源自武汉病毒和舟山病毒(MG772933)的S蛋白比较时,发现插入片段存在于约265、450、480、495和690位。这表明印度组所做的比对太过简略,选取的序列数量不足,放大了序列间的差异性。

另一方面,他们选取的“插入片段”太短,与HIV同源性较好的片段1和2只有6个氨基酸,片段3和4长一些(8-12个氨基酸),但HIV对应片段中又出现了进一步的插入片段,而且没有全序列的比对做背景。 他们对于这些片段功能的确认方式只是基于同源建模的模拟,而缺少结构、生化和细胞水平的证据。这种同源性分析只能说聊胜于无。
4) 云南蝙蝠病毒
MN996532 RaTG13于2020年1月27日提交,印度研究组的预印文本是在1月31日bioRxiv上线,几天后撤稿。明显印度方面的撤稿不是由于RaTG13这个事先已经的序列,作为严谨的科研工作者,在文章上线的最后一刻应该对相关的科研进展进行复核,况且是这种实效性很强的研究,而至少3天的时间印度人都没有发现和讨论RaTG13的问题。他们的撤稿也是分析方法和结论出现了多处问题,不仅仅限于RaTG13(如 3)中的一些讨论)。所以强调RaTG13的”火速”提交与印度撤稿的关系我觉得并不能让人信服。
5) 演化树分析
下面Tang兄提及了溯源的问题,我就不多说了
6) 本兄所说的
非天然碱基对这个表述的指向性是非常强的,这个消息是否有具体的出处
P.S.: NCBI和BLAST国内都是可以用的
- 待认可未通过。偏要看
既然这里有真懂行的,要把这个楼继续往上砌的话,我也得认真一点,所以我就去把2015年那篇NATURE的PAPER找来看了。
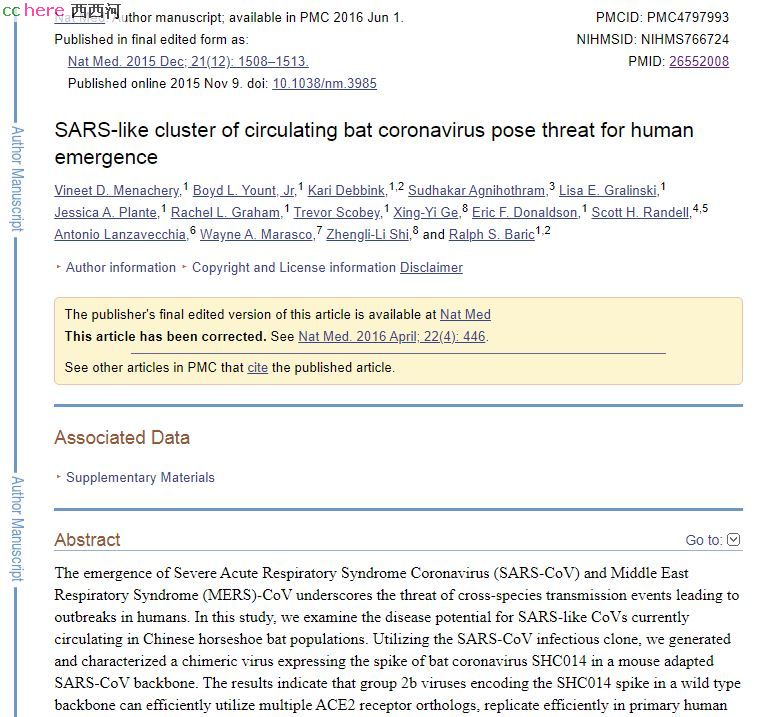








很感慨啊。
首先,《nature》是比《英格兰浪人报》上档次。太医院荞鸡-高拉了几个从七品御医,攒的那个《度支核数折》,也就掺了点珠算口诀,那个朕还看得懂。《Nature》太硬核了,太子太傅没教过,朕真的泪目 。
。
但是我能八卦,呼朋引伴请教一番,多少看出字缝里写了什么。
最重要一点是,我之前犯了个错误。2015年那个Paper,石研究员不是“并列通讯作者”,通讯作者是第一位VDM和最后一位RSB。石排在倒数第二位,用一个“&”,与RSB并列,我一个粗心,就以为她是“并列通讯作者”了。

这个实验项目,就是通过嵌合的方式,“行上帝所行之事”,创造生物。美国银的出发点非常有意思,就是“模拟未来可能会出现的危险微生物”,志愿充当“蓝军”去朱日和耍耍。这个脑回路之清奇,我到现在都没有想明白。但是这个项目,是正儿八经经过北卡罗莱纳大学基因工程系,北卡大学,美国卫生总院(NIH),操蛋处(CDC,当然这是美国操蛋处,这里还轮不到中国操蛋处蹭热度)等等层层审批,才立项的。资金来自卫生总院和中国国家自然科学基金。这可以从论文里“SARS-CoV is a select agent”和“Acknowledgments”这二节里看到。
在美国,大学的生物科技实验室,都是P2或者P3级别。这就产生了一个怪现象,这个Case,以北卡大学的P3实验室为主导,而辅助者,居然是中国唯一的P4实验室。这就好比运-12飞机,在哈飞总装,但机翼是由波音西雅图供应的。这个倒转的原因,就是中国的科研人员还没有经验,只能靠 “带资进组,带设备进组”,拿一个“第二女配角”的戏份。
技术上讲,非典级别的“变态病毒”,是可以在P3实验室分拆组装着玩儿的。但因为Sars病毒非常具危险性,这种刀尖跳舞的活儿,最好还是放在P4,因为P4的“防泄漏”安全系数要高很多。这个项目,基本全程在美国P3实验室完成,包括用老鼠做活体实验。“SARS-CoV is a select agent”这一节里,一再强调该州立大学实验室管理的完备性,就是在“硬件级别”这一点上心虚。这说明武汉病毒所确实非常弱势。
那么石研究员起了什么作用呢?第一,带资。第二,拆分组合非典这种高危级别的病毒,必须由能处理此类病毒的实验室,把病毒里面的所有基因打散克隆出来,再把“散件”提供给没有处理整株病毒能力的实验室作研究,比如去开发疫苗抗体。武汉P4,等于是台积电这样的芯片厂,把SARS病毒的基因分拆克隆好后,像成品芯片一样,供应给美国P3们,去组装成Iphone。
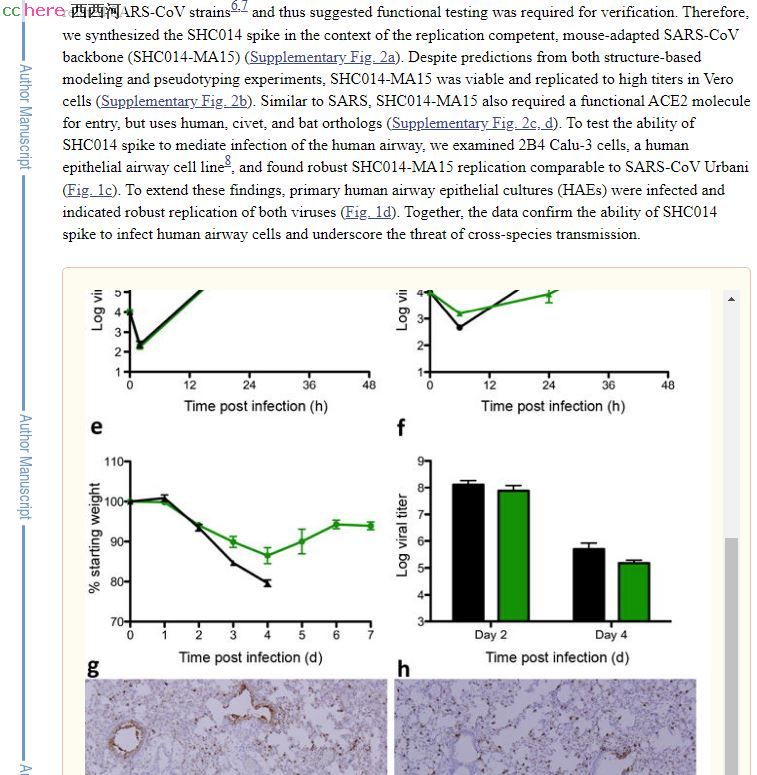
在这个项目里,石团队额外还做了一个工作,她做了一个试验,拿到一个数据。这个数据在Supplementary Figure 1里面,不能算是文章的核心数据。
石团队这个子项目,不是用美国人组装完了的,有传奇意义的“人造病毒”直接作活体试验,而是用实验室最常规的Lentivirus来模拟测试感染能力,这方式又称为Pseudovirus。
简单说,整个项目中, “搭积木”的所有关键桥段,武汉P4实验室插不上手。在《nature》这样硬桥硬马的平台发Paper,会要求写明每个作者的贡献,在Author Contributions这一节里,描述得非常清楚,中方就是一个石,一个葛姓实验室操作员。
第二,说说资金。NIH在2013年就启动这个项目,给了资助。但到了2014年,由于学术界对于这种 “没有威胁,创造威胁也要上”的马鹿魔幻,相当反感,结果NIH犹豫了,重新审核,但最后还是放行了,因为前期的钱已经被北卡的蛋头骗子们骗走,不走完对不住纳税人。但是在信仰上帝的煎熬中,NIH一等北卡出了Paper,就卷铺盖走人,发誓再不造上帝的反了。如果北卡不忘初心,砥砺前行,那么一则,按照蛋头骗子群里的江湖道义,这个Idea是北卡的,石团队不可以窃取;二则,石团队就算窃取,再怎么赶,肯定比北卡要落后好几年,轮不到你再上春晚。但恰恰是北卡没有资金,被迫歇菜了(但美国军方未必歇菜),那么石团队就理直气壮 “拿来”了,反正病毒所完颜铁所长除了拉大提琴,其他懂得有限,哪里压得住下面的石大帅。
先八卦到这里。
北卡利用武汉提供的配件捣鼓的玩意不一定只有论文上的那些,更不一定全部告诉武汉P4。实际上北卡团队都做了什么,只有他们自己知道。
但中国自己一定不能自废武功转移产业去国外。
产业可以提高质量,但不能废,还必须尽可能的完善产业配制。