主题:【原创】基于西西河发帖时间戳的河友发帖习惯分析 -- 菜根谭
- 共: 💬 52 🌺 415 🌵 5
果然是理不辩不明,我觉得这个工作值得一个主贴。
首先感谢 @兰州人 和某匿名河友,你们第一次提出相关性分析,说实话,开始时候我没想好怎么做。看完匿名河友的发言,一下子清晰了很多。
【原创】军情六局M16入驻西西河?(西西河发帖时间调查报告)
数据来源:www.talkcc.org
数据提取方法:爬虫(受上述河友启发)。
处理软件:Matlab
1. 按照上述匿名河友帖子启发,这个分析中也采用了类似的发帖频率图,但是后续我还要分析一堆被我屏蔽和怀疑的ID,这些ID发帖数量基本在100-500之间,如果采用30分钟的时间分辨率,48个点造成曲线噪声过大。
首先看下我的分析图是否和匿名河友的分析结果相似:
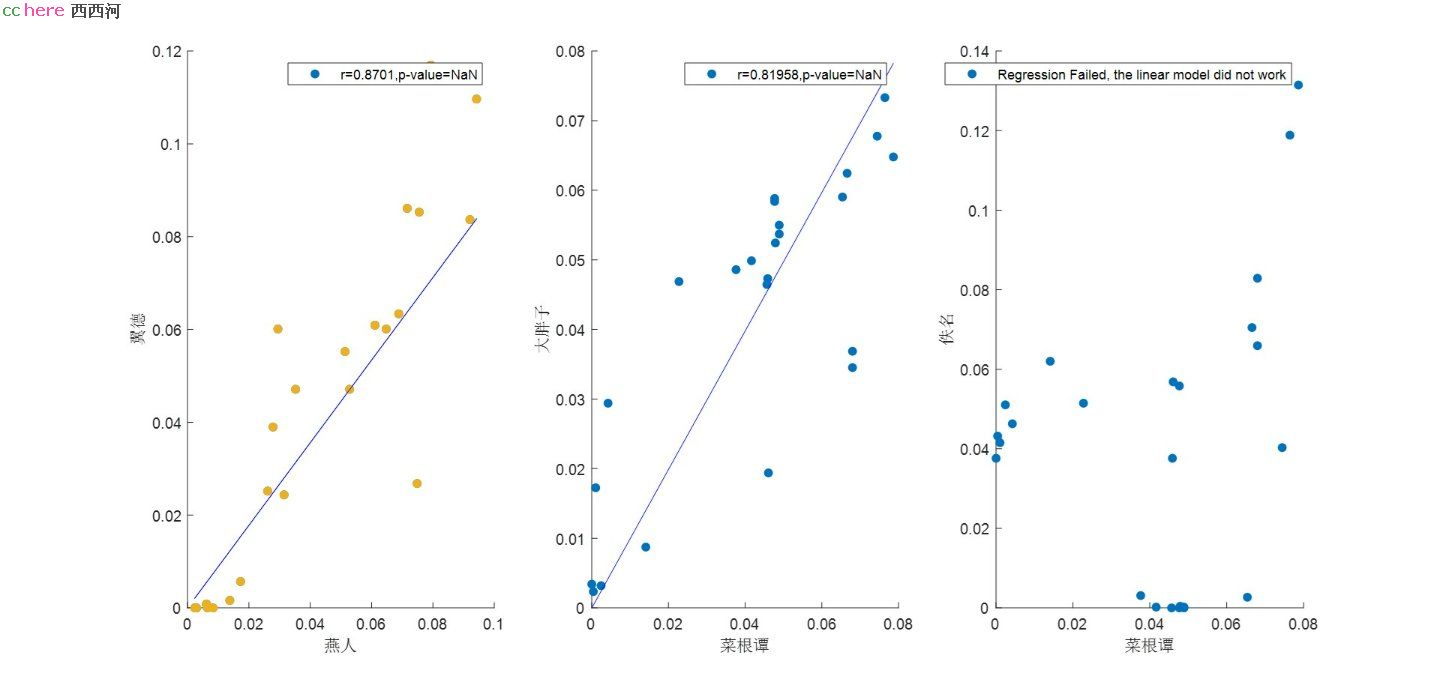
可以看到:
1. 时间分辨率下降到1小时不影响分析结果;
2. 燕人和翼德数据强相关,R=0.87;
3. 菜根谭和大胖子数据也有比较强的相关性,R=0.82;
4.我也引入了一个不具名的佚名河友数据,可以看到,相关性消失了。
(在Matlab中,我使用了Regress函数,在相关性很差时,Regress会返回负值R2,代表线性模型失效,所以这个无法给出R值)。
所以说以上匿名河友分析的数据是有效的,但是.....我是大胖子的马甲吗?
最简单的分析办法是引入另一个已知变量
@达雅
因为达雅批评我败人品,既然败过一回,那我就破罐子破摔,把达雅的数据也引入进来。
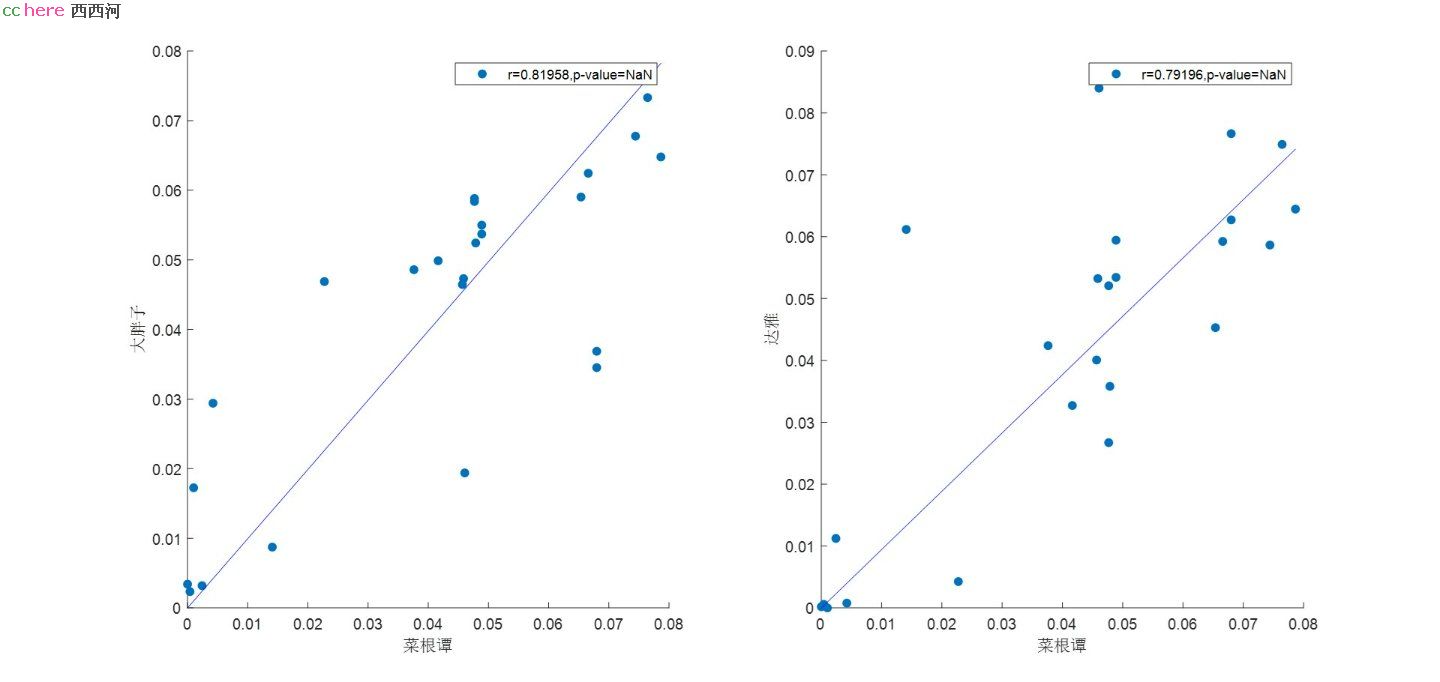
可以看到:
1. 我和大胖子的相关性R=0.82;
2. 我和达雅的相关性R=0.79;
这两个数字应该不能算是明显不同吧?
那么,那么,@达雅, 你也是我或者大胖子的马甲吗?
抛弃是不是马甲不谈,实际上这个相关性带来的很多有意思的结果,也给我Matlab编程创造了方便。
要下车了,先搞这么一段,其他有时间再发。
土鳖抗铁牛。
本帖一共被 1 帖 引用 (帖内工具实现)
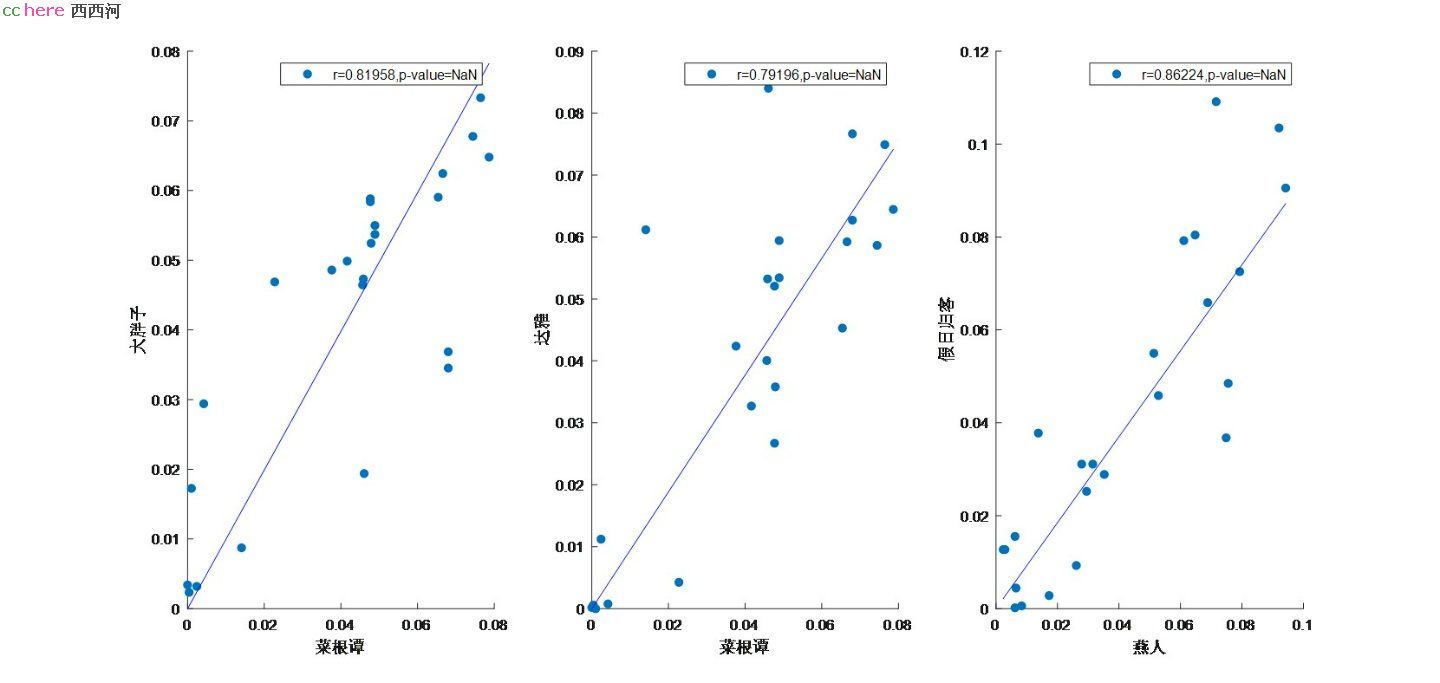
按照上文中的分析方法,可以看到:
大胖子vs菜根谭:R=0.82;
菜根谭vs达雅: R=0.79;
燕人:假日归客:R=0.86;
聪明的读者,发现问题了么?这三对难道互相都是马甲吗?
所以问题在哪儿呢?这种相关性到底在寻找什么?
绿色蔬菜的这个解读是最准确的。
我们认为人都是随着日升日落起居作息的,所以只要时间足够长,每个人的作息时间实际是在时间轴的一个平移。
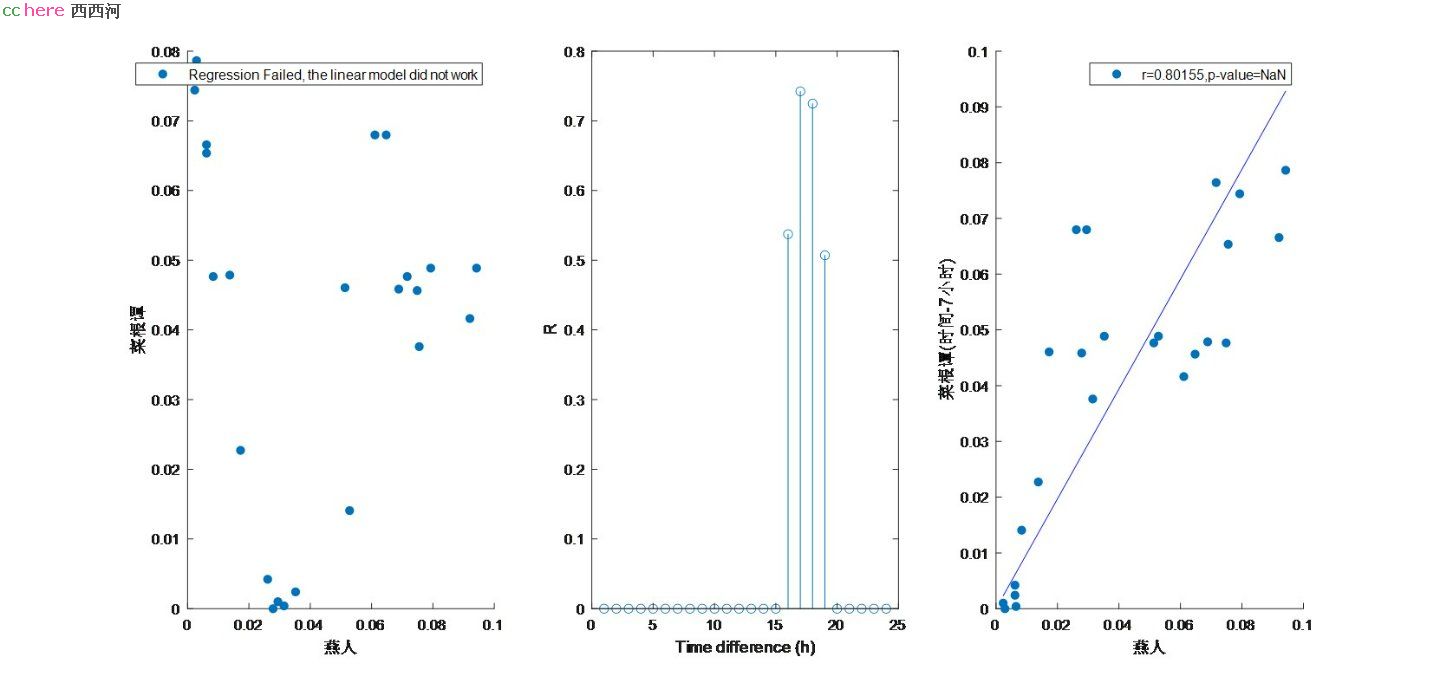
用我对燕人的数据举例:
图1显示我们的数据没有相关性;
图2是固定燕人的数据,但是我的数据伴随着时间轴进行平移,并再次与燕人的数据进行Regress分析,由于Matlab的原因,Regress函数的R2会返回负值,这种情况下说明线性拟合不成立。我直接设置R=0;
从图2可以看出,当我的数据平移17个小时的时候,和燕人的数据出现最好的相关性;R接近0.8,如图3所示;
什么意思呢?也就是说:燕人和我的作息时间差7个小时。之前从我前一系列分析看到,,他在英国GST时区,我在北京时区。看起来我们作息差1个小时,这个解释合理吗?
只看图3,难道燕人是我的马甲吗?
下一步,让我们用一些已知老河友的数据验证下这个理论是否正确:
因为燕人所在时区是GST, 将作为后续分析时间轴基准:
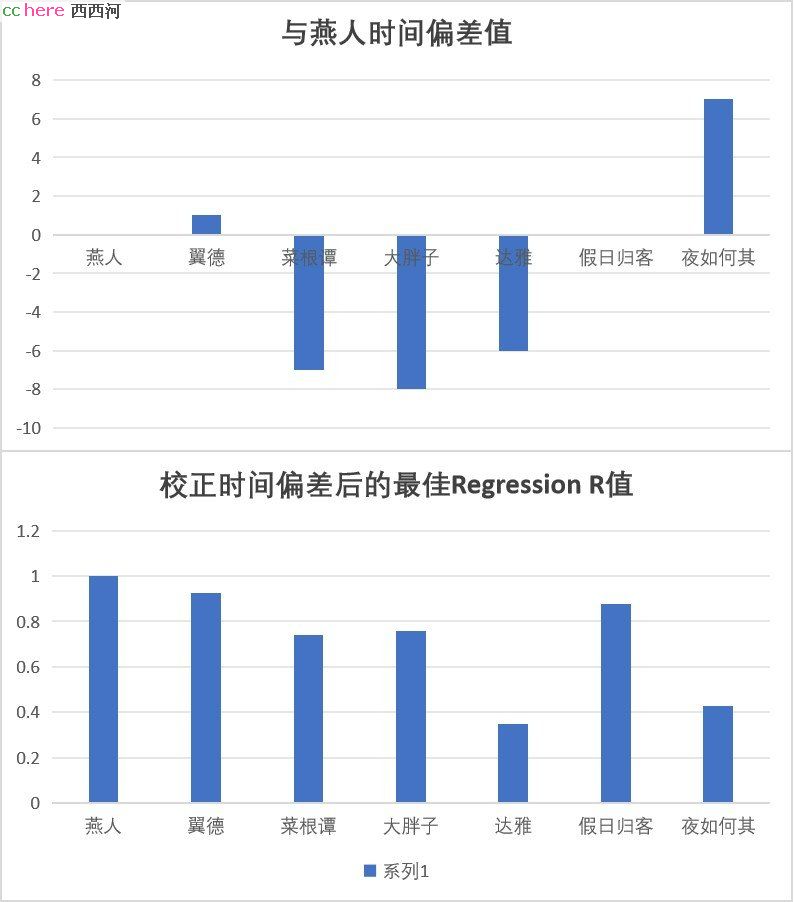
相对燕人:
翼德:+1; 翼得2022后注册,而燕人数据覆盖了之前10多年的数据;所以有偏差;
菜根谭:-7: 东8区,作息晚1小时;
大胖子: -8:东8区,作息时间类似;
达雅:-6:东8区,作息时间早1个小时;
假日归客:0,西1区,作息查一个小时;
夜如何其:7,西5区,作息晚2个小时;
以上数据证实时间分析是可行和准确的。
土鳖抗铁牛。
【原创】军情六局M16入驻西西河?(西西河发帖时间调查报告)
我下面要分析的这些ID都被我屏蔽了,还是用燕人的数据(英国GST时间)作为时间基准轴.
先说结论:
这些ID未必是阉人直接运作的马甲,但是很显然和阉人团队具有紧密关系,生活作息比阉人晚2-3个小时,显然是有组织的在发文。这是一个团伙!
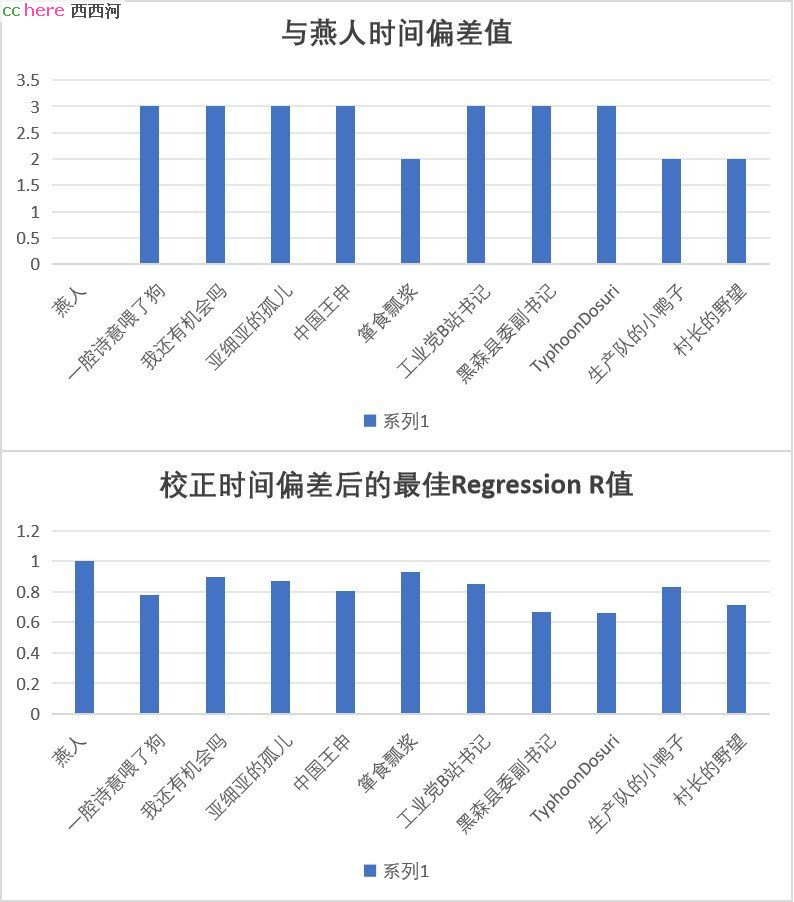
这些数据应该很有说服力了吧?
他们作息时间对比阉人大概是延迟了2-3个小时,经过时间校准后,和阉人发帖规律相关系统R 在这个范围内:【0.7~0.92】;
这些ID本身之间发帖时间几乎是一致的,相互之间偏差在1小时之内,已经在误差范围内。
这些被分析的ID有各种各样的人设:社会底层,台湾ID,左派,右派;但是他们的数据集聚了,并且都一直被阉人团伙以保护多样性的名义保护。
@铁手
他有那么大能耐吗?能造成多大的破坏?感觉也就是写的食谱和电影可以看看,其它的基本没注意过。
在此帖显示你果然不具备普通理工科研究生的水平中,对你的职业估计在这个帖子里被完全印证了。虽然你可以请他人帮你分析数据,但是你完全缺乏正确理解这些结果的能力。你的职业习惯让双标已经深深植入你的骨髓,导致你完全不理解科学或者工程中的对照的概念。
作为一个学术老兵,虽然我没有能力掌握爬取数据这些新技术,但起码我有解读数据的能力。我先按你的逻辑走一遍,推断一下荒谬之处,再给其他旁观者讲一下正确的思路。
1. 你现有逻辑的延伸导致的悖论
1.1 你首先是试图采取一个对照,假定你和达雅不是互为马甲,然后以你们相关系数较高来反证你和大胖子也不是互为马甲。但是这个逻辑如果成立,那就证明了这个所谓的时间指纹或者时间戳的方法根本无效,后续所有的分析都失去了基础。你可以删掉从第一个帖开始的所有数据分析了。
1.2 所谓时间偏差的分析。你试图用发帖时间分布的时间差来代表ID所在时区。比如你捡取的国内网友比燕人早若干小时,而你捡取的美洲网友比他晚几个小时。然后在另一个帖子,你指出若干网友比燕人晚若干小时所以是马甲或者有什么特殊关系云云。但是如果延续你的逻辑,这些网友应该存在于美洲和英国之间,即大西洋正中。玩过大航海时代的网友,知道确实大西洋中有某些有人小岛。但是这个有点太匪夷所思了。
我觉得 @假日归客 网友的分析这些共识没有出现在你的主贴里,即这些网友有着非体制内工作的假说更加符合他们发帖时间分布的现实。更广义的说,虽然这个时间差可能由时区差异和生活差异造成,但对这几个网友,用后者解释数据更可信。
1.3 至于对所谓时间差异校正后的相关性,更是离谱。如果把你的两个帖子对着看,发现你怀疑的燕人马甲群,这个数据的分布范围很广。其中有些低于0.7,而你和燕人的这个指标反而高于0.7,也就是说,如果相信这个数字标准,你自己难道是燕人拿来捧哏的吗?而那些网友此数值最高的不过0.9,和假日归客相当。那西西河绝大多数网友都是燕人的马甲或者什么团伙。西西河已经不是铁手的,而是燕人的了。这怎么可能呢?
所以可以看出你的脑子一团浆糊,完全不知道自己在说什么。如果是受过研究生,或好大学的做过本科毕业设计的大学生,都不能犯你这样的错误。
2. 我给大家解释一下可能的背后逻辑。
2.1 这个【讨论】受某网友启发,关于马甲的简单分析和讨论匿名网友的分析会比较依赖时间分辨率。一个极端情况,时间分辨率为24小时,那所有的人互相都是强相关,因为数据都是一个点1。随着分辨率逐渐提高,相关系数整体会下降。真正相关的ID下降较慢,而不真正相关的下降较快。所以存在某两个ID在较低分辨率下相关强,另一个较高分辨率下相关弱的情况。那个文中作者把所有分析放在同一个参数下,并且有公开承认马甲(高)和无关网友(低)的对照,才比较可信。即使在那样条件下,也只能说AB相关性高于CD,所以AB互为马甲概率高于CD,而不是给出绝对的判定。如原文中提及的青春、机会两网友相互或和燕人网友相关低于菜和胖。但菜和胖未必是互为马甲,也可能隔壁工位一起上班打卡的同志。
2.2 和 2.3 可以放到一起说。对于一个分布,我们可以找分布中心,和分布形状来描述。如正态分布的均值和方差。但是对于真实生活数据解读,两者是不能随意分割去解释的。如前所述,分布中心的差别,可能是生活习惯和时差等多个因素造成,而分布形状也依赖于生活习惯,所以把这两个分开讲本身就缺乏客观理性,或者说缺乏物理意义。更何况楼主两个方向的解释都在事实面前遇到难于逾越的困难,却不知悔改,也是奇葩。属于张三锯掉脚,赵二穿上高跟鞋,都能跟李四差不多高,所以他们和李四一定有关系这种完全驴唇不对马嘴的栽赃。
另外,还有一个数据的诚信问题。虽然分布中心和分布形状不能严格倒推原始数据,但看到在你第二个帖中,以燕人为参照,达雅的数据分布中心和分布形状和你数据的差别,都远大于你和大胖子的数据差别,却能在第一个帖中,和你的相关性与你和大胖子相关性非常接近。这是不符合现实数据规律的。这个需要能够读取数据的网友去验证。
你急吼吼列出一些ID,生啦硬凑非要去和燕人网友扯上关系,还不断找 @铁手 告状,在我们旁观的人看来,就是你和同伙多次吵架吵不过人家,被全方位压制,所以才要把一群不同观点的人一起封为燕人马甲或者什么M16团体。准确的说,就是熊孩子心态。打架不过,希望有一个亲爹来帮自己摆平。和普通院系的政工干部去书记那里告状若干任课老师背习主席语录组团打瞌睡有什么区别?但是你这样的一个天天满嘴脏话骂街的ID,不要说 @铁手 ,就是多数网友也要爱惜羽毛和你保持距离。
国内高校教师,若上课要面对聪慧的大学生,若科研要面对挑剔的审稿人,都不会犯你这里犯得这么多低级错误。只有那些团委、学工的人,只要会拍领导马屁,对学生甚至正牌老师都颐气指使惯了,才会为了箭头画靶子,处处双标而不自知。
上网写字就是一件浪费时间的事情。不是什么好事。这是前提。但是作为成年人,特别是海外的成年人,有时候使用一下汉语都不容易。而谈一些类似政治,军事的话题更难。朋友,家人哪怕聚会,谁没事说这个,显得很二啊。 所以有这么一个地方消遣消遣。 特别好的是这个地方还非常的小众,来的人不多。否则一顿瞎写,圈子就这么大,过两天被熟人认出来了不是很尴尬。
我能理解大家观点不同,甚至有时候恶语相向。 有些人不用脏话,冷嘲热讽一下;有些人直接上傻X之类的语言。在我看来并无高低之分。后者多少让人感到不适,但也还好。
我隔着屏幕都感觉尴尬的抠脚的就是一些所谓XX进驻了,拿钱发帖了,控制舆论了。年轻的时候觉得自己挺重要,自己挺牛逼,虽然现在想起来还隐隐有些尴尬,但毕竟还有借口,年轻嘛。 这么大岁数,自己几斤几两还不清楚? 你能随意发言的地方能有多重要?钱是那么好挣的,随便敲几个字就有钱拿? 谁有办法麻烦介绍个路子给我。
我深恶痛绝的就是一帮ID追着另几个ID谩骂。不针对具体的帖子,具体的内容,就是看见了就骂,连信息交流都没有。你们骂的殖人,阉人起码可以转载几个英语的新闻,我看他就知道有这么个新闻,不看他可能还得自己少。你们除了骂他,连转载个新闻,哪怕国内新闻的能力都没有。你们骂的汉奸起码写东西前后通顺,图文并貌。辛辛苦苦我估计怎么也得写个个吧小时,你们上来20多个字还加上一堆脏话。不喜欢别看就是了。难道你在生活中也是某太子党,出门看什么不顺眼直接骂就完了?
我一般看见了就躲,不让你那几十个字浪费我5秒钟。但是确实这种东西越来越多了。过去是饭里有沙子,现在是沙子里有饭。希望不要未来变成河水里面淘金矿。
你的数据说明部分挺有道理,匿名很没有必要。我已经被燕人一伙批评到连大学都没毕业了,您这个学工干部对我的评价太高了,受不起。要不你们统一下说法?
大数据本来就是个观察而已,单维度信息本来就很难搞,只有suggestive的结果就不错了。
你后续的数据分析建议我会仔细考虑下,感谢建议。
我真正要证明的是这个帖子里:
继续讨论与回复:他们完全可能在欧洲,但是他们宣称是在国内的!
所谓的生活习惯不同是解释不了接近10个小时的作息偏差的。那些ID有相当部分是宣称生活与中国时区的。
在这个帖子里:
这几位河友宣称自己在国内或者台湾高雄的。这和他们活跃的时区不符合。
这些被我屏蔽的IP相当部分都在撒谎。
这个事情的起因在哪儿?
是铁手开放送花名单,有些奇怪的事情被注意到:
燕人给亚细亚的孤儿骂毛主席的帖子送花;
所谓修行,就是无时无刻都训练着放松自己,最终要面对答案时比较平静,期待不必太高。
如果给出的这个解释和定论,自己觉得还过得去,那就上对得起父母,下对得起后代,这辈子差不多可以了。至于横向比不比,各人丰俭随意。
怕就怕老来后悔,深觉以前哪一步走岔了,怨天尤人放不下。头顶三尺有黑气,闻名方圆数百里;一入悔门深似海,拖人下水耍无赖。反正我不好了,凭什么你们还能好好过?
物质不灭,戾气也不灭。人是很难渡过自己给自己设的坎的,因为随着外部的压力/内心的焦虑,这坎天天在增高。我们每个人都如此,所以要紧的是童子功,如果以前修为尚可,身体也好心理也好,还OK,那等到老来焦虑时,这坎原先比较低矮,再长也高不到哪里去,等高过喜马拉雅那天,我都嗝屁了。
其实哪一步对,哪一步错,都是幻象泡影------当然唯物主义者不认这个理儿。
铁手作为这个网站的拥有者和管理者,拥有上帝视角,匿名对我们有效,对铁手而言和裸奔没区别。
铁手清楚的知道某些id就是马甲,而且也知道是谁的马甲,比如他曾直接回帖“中国王申”说:“你就是马甲。”导致此后中国王申销声匿迹。
铁手制定的规则是允许使用马甲的,甚至搞出了马甲的二阶版本——“匿名”,实际上是匿id,id本来就是匿名的嘛。
铁手也清晰的知道你和我到底是不是马甲,在铁手面前没必要申辩,他啥都知道。他想封马甲直接可以动手,不必谁来跟他举报,一切的根源是铁手不想。
如果能明辨是非,无须辨认马甲。
如果不能明辨是非,更无意义。
沉默的是大多数,绝大多数,在这个方向多努力。
我们气人宗,一向是看热闹不嫌事儿大滴。
但菜和胖未必是互为马甲,也可能隔壁工位一起上班打卡的同志。
这是一种情况;
还有就是菜和胖同为室友,用一个Wi-Fi路由器。老铁查了IP都不会认为他们是马甲;
等等等……还有其他各种情况,艾特老铁是没用的
首先声明一点:我玩鉴别马甲,是很多年前的事了。很多相关技术在不断进步,因此我写的这些,只能是仅供参考。
用发帖时间相关性鉴别A是否是B的马甲,是基于一个主观假设:即A与B如果发帖时间相关性很高,那么他们大概率互为马甲。
很可惜,这种假设是比较简单粗糙甚至粗暴的。一个极端的反例:如果A看B不爽,且有大量时间泡在河里,时时关注B的每一个发帖。一旦B发了任何贴,A立即追着发帖骂 ----- 这种场景下,A与B的发帖相关性接近于1.0 ---- 能说A是B的马甲嘛?
更一般性的例子,譬如我生活在北美,一般周末或者美国特有的假期,发帖时间比较多。如果有另外一位不相识的但同样生活在北美的河友也是这么个习惯,那么我与他就一定互为马甲?
想有效的鉴定马甲,技术路线有很多种。但是,仅用发帖时间相关性----- 这么一个特征向量,是远远不够的。严格说,这个特征向量,尚未触及到鉴定马甲的真正技术实质。
比较专业的方法,是通过用户的发帖文本特征的相似性来鉴别每一个用户。对每个待分析的用户,抓取其发帖的大量文本,进行自然语言处理(NLP),即进行分词、语法分析、语义分析、建立实体(entity)数据库, 提取出所有相关文本特征向量(X个)。因为发帖类型不同,可能还得分类(Classification),当年我们作新闻时,分为八大主类、N个小类,比如政治新闻用语肯定与商业、体育等类完全不同(如何有效分类,则是另一个专业技术范畴,这里略过不谈)。
完成以上工作后,先拿其中的80%数据作为训练样本,通过某种Machine Learning算法(简单的比如SVM),学习出每个特征向量的权值。
最后就是用剩余的20%数据,测试你训练的结果是否有效。如果无效,那就得回头抓取更多的文本样本,作更细化的分类,提取更多的文本特征向量 ---- 重新训练,如此循环。
另外,由于用户的发帖习惯会随着时间改变,所以训练得不断更新。
看到这里:我真正的想说的话,兄台应该已经明白了 ---- 您真值得花这个功夫搞马甲鉴定嘛?
如果真想搞,不如考虑去Google、Bing、百度做个Sabbatical ,看看人家专业公司的现成工具都用了啥。
毕竟隔行如隔山,很多看似简单的事,也是需要比较多的技术积累的。
下河嘛,聊个天而已。合则回,不合则划过而已。有那个功夫,看点开心的帖子,不亦乐乎?