主题:【原创】解剖Twitter 【1】 -- 邓侃
- 共: 💬 68 🌺 272
【5】数据流与控制流
前文说到,Twitter有两大看点,缓存(Cache) 与消息队列(Message Queue)。消息队列的作用,是“隔离用户请求与相关操作,以便烫平流量高峰 (Move operations out of the synchronous request cycle, amortize load over time)”。
通过让Apache进程空循环的办法,迅速接纳用户的访问,推迟服务,说白了是个缓兵之计,目的是让用户不至于收到“HTTP 503” 错误提示,“503错误” 是指 “服务不可用(Service Unavailable)”,也就是网站拒绝访问。
大禹治水,重在疏导。真正的抗洪能力,体现在蓄洪和泄洪两个方面。蓄洪容易理解,就是建水库,要么建一个超大的水库,要么造众多小水库。泄洪包括两个方面,1. 引流,2. 渠道。
对于Twitter系统来说,庞大的服务器集群,尤其是以MemCached为主的众多的缓存,体现了蓄洪的容量。引流的手段是Kestrel消息队列,用于传递控制指令。渠道是机器与机器之间的数据传输通道,尤其是通往MemCached的数据通道。渠道的优劣,在于是否通畅。
Twitter的设计,与大禹的做法,形相远,实相近。Twitter系统的抗洪措施,体现在有效地控制数据流,保证在洪峰到达时,能够及时把数据疏散到多个机器上去,从而避免压力过度集中,造成整个系统的瘫痪。
2009 年6月,Purewire公司通过爬Twitter网站,跟踪Twitter用户之间“追”与“被追”的关系,估算出Twitter用户总量在 7,000,000左右 [26]。在这7百万用户中,不包括那些既不追别人,也不被别人追的孤立用户。也不包括孤岛人群,孤岛内的用户只相互追与被追,不与外界联系。如果加上这些孤立用户和孤岛用户群,目前Twitter的用户总数,或许不会超过1千万。
截止2009年3月,中国移动用户数已达 4.7亿户[27]。如果中国移动的飞信[28] 和139说客[29] 也想往Twitter方向发展,那么飞信和139的抗洪能力应该设计到多少呢?简单讲,需要把Twitter系统的现有规模,至少放大47倍。所以,有人这样评论移动互联网产业,“在中国能做到的事情,在美国一定能做到。反之,不成立”。
但是无论如何,他山之石可以攻玉。这就是我们研究Twitter的系统架构,尤其是它的抗洪机制的目的。
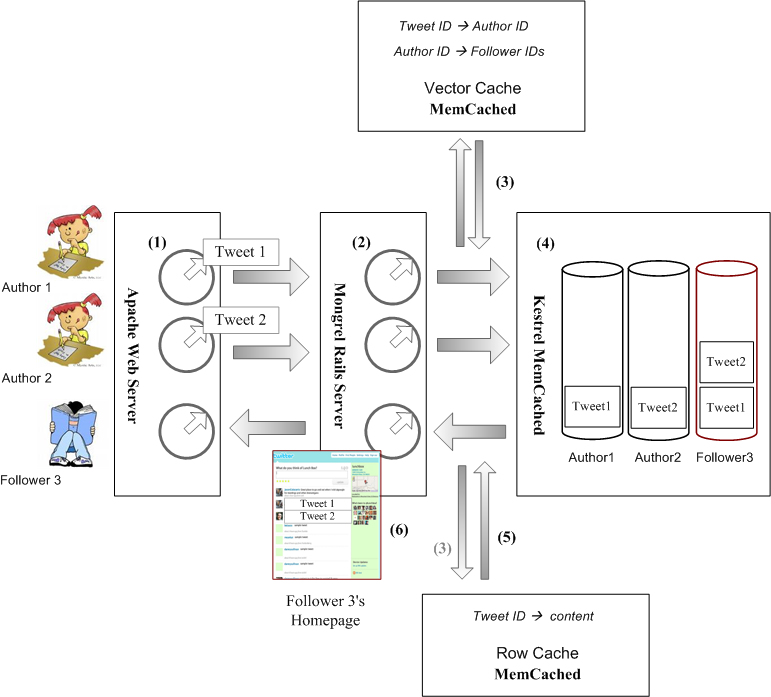
Figure 7. Twitter internal flows
Courtesy http://farm3.static.flickr.com/2766/4095392354_66bd4bcc30_o.png
下面举个简单的例子,剖析一下Twitter网站内部的流程,借此考察Twitter系统有哪些机制,去实现抗洪的三要素,“水库”,“引流”和“渠道”。
假设有两个作者,通过浏览器,在Twitter网站上发表短信。有一个读者,也通过浏览器,访问网站并阅读他们写的短信。
1. 作者的浏览器与网站建立连接,Apache Web Server分配一个进程(Worker Process)。作者登录,Twitter查找作者的ID,并作为Cookie,记忆在HTTP邮包的头属性里。
2. 浏览器上传作者新写的短信(Tweet),Apache收到短信后,把短信连同作者ID,转发给Mongrel Rails Server。然后Apache进程进入空循环,等待Mongrel的回复,以便更新作者主页,把新写的短信添加上去。
3. Mongrel收到短信后,给短信分配一个ID,然后把短信ID与作者ID,缓存到Vector MemCached服务器上去。
同时,Mongrel让Vector MemCached查找,有哪些读者“追”这位作者。如果Vector MemCached没有缓存这些信息,Vector MemCached自动去MySQL数据库查找,得到结果后,缓存起来,以备日后所需。然后,把读者IDs回复给Mongrel。
接着,Mongrel把短信ID与短信正文,缓存到Row MemCached服务器上去。
4. Mongrel通知Kestrel消息队列服务器,为每个作者及读者开设一个队列,队列的名称中隐含用户ID。如果Kestrel服务器中已经存在这些队列,那就延用以往的队列。
对应于每个短信,Mongrel已经从Vector MemCached那里知道,有哪些读者追这条短信的作者。Mongrel把这条短信的ID,逐个放进每位读者的队列,以及作者本人的队列。
5. 同一台Mongrel Server,或者另一台Mongrel Server,在处理某个Kestrel队列中的消息前,从这个队列的名称中解析出相应的用户ID,这个用户,既可能是读者,也可能是作者。
然后Mongrel从Kestrel队列中,逐个提取消息,解析消息中包含的短信ID。并从Row MemCached缓存器中,查找对应于这个短信ID的短信正文。
这时,Mongrel既得到了用户的ID,也得到了短信正文。接下去Mongrel就着手更新用户的主页,添加上这条短信的正文。
6. Mongrel把更新后的作者的主页,传递给正在空循环的Apache的进程。该进程把作者主页主动传送(push)给作者的浏览器。
如果读者的浏览器事先已经登录Twitter网站,建立连接,那么Apache给该读者也分配了一个进程,该进程也处于空循环状态。Mongrel把更新后的读者的主页,传递给相应进程,该进程把读者主页主动传递给读者的浏览器。
咋一看,流程似乎不复杂。“水库”,“引流”和“渠道”,这抗洪三要素体现在哪里呢?盛名之下的Twitter,妙处何在?值得细究的看点很多。
Reference,
[26] Twitter user statistics by Purewire, June 2009. (http://www.nickburcher.com/2009/06/twitter-user-statistics-purewire-report.html)
[27] 截止2009年3月,中国移动用户数已达4.7亿户. (http://it.sohu.com/20090326/n263018002.shtml)
[28] 中国移动飞信网. (http://www.fetion.com.cn/)
[29] 中国移动139说客网. (http://www.139.com/)
【6】流量洪峰与云计算
上一篇历数了一则短信从发表到被阅读,Twitter业务逻辑所经历的6个步骤。表面上看似乎很乏味,但是细细咀嚼,把每个步骤展开来说,都有一段故事。
美国年度橄榄球决赛,绰号超级碗(Super Bowl)。Super Bowl在美国的收视率,相当于中国的央视春节晚会。2008年2月3日,星期天,该年度Super Bowl如期举行。纽约巨人队(Giants),对阵波士顿爱国者队(Patriots)。这是两支实力相当的球队,决赛结果难以预料。比赛吸引了近一亿美国人观看电视实况转播。
对于Twitter来说,可以预料的是,比赛进行过程中,Twitter流量必然大涨。比赛越激烈,流量越高涨。Twitter无法预料的是,流量究竟会涨到多少,尤其是洪峰时段,流量会达到多少。
根据[31]的统计,在Super Bowl比赛进行中,每分钟的流量与当日平均流量相比,平均高出40%。在比赛最激烈时,更高达150%以上。与一周前,2008年1月27日,一个平静的星期天的同一时段相比,流量的波动从平均10%,上涨到40%,最高波动从35%,上涨到150%以上。
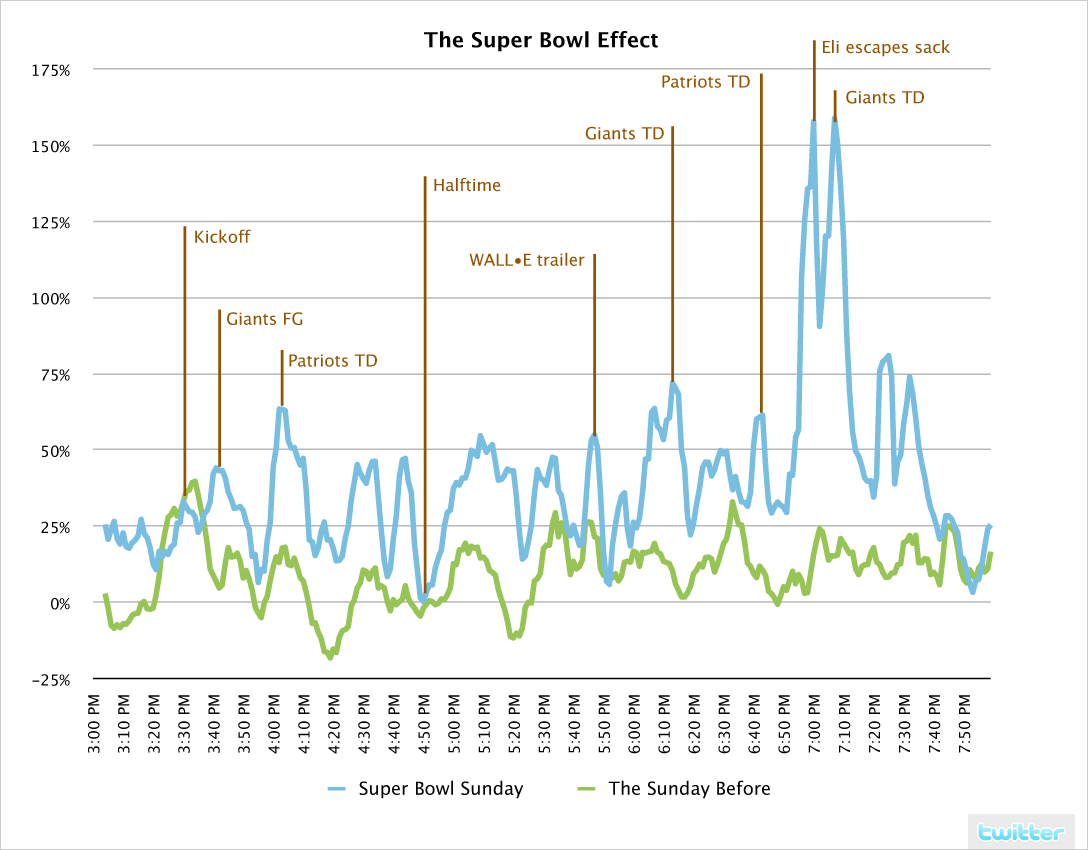
Figure 8. Twitter traffic during Super Bowl, Sunday, Feb 3, 2008 [31]. The blue line represents the percentage of updates per minute during the Super Bowl normalized to the average number of updates per minute during the rest of the day, with spikes annotated to show what people were twittering about. The green line represents the traffic of a "regular" Sunday, Jan 27, 2008.
Courtesy http://farm3.static.flickr.com/2770/4085122087_970072e518_o.png
由此可见,Twitter流量的波动十分可观。对于Twitter 公司来说,如果预先购置足够的设备,以承受流量的变化,尤其是重大事件导致的洪峰流量,那么这些设备在大部分时间处于闲置状态,非常不经济。但是如果缺乏足够的设备,那么面对重大事件,Twitter系统有可能崩溃,造成的后果是用户流失。
怎么办?办法是变买为租。Twitter公司自己购置的设备,其规模以应付无重大事件时的流量压力为限。同时租赁云计算平台公司的设备,以应付重大事件来临时的洪峰流量。租赁云计算的好处是,计算资源实时分配,需求高的时候,自动分配更多计算资源。
Twitter 公司在2008年以前,一直租赁Joyent公司的云计算平台。在2008年2月3日的Super Bowl即将来临之际,Joyent答应Twitter,在比赛期间免费提供额外的计算资源,以应付洪峰流量[32]。但是诡异的是,离大赛只剩下不到4 天,Twitter公司突然于1月30日晚10时,停止使用Joyent的云计算平台,转而投奔Netcraft [33,34]。
Twitter弃Joyent,投Netcraft,其背后的原因是商务纠葛,还是担心Joyent的服务不可靠,至今仍然是个谜。
变买为租,应对洪峰,这是一个不错的思路。但是租来的计算资源怎么用,又是一个大问题。查看一下[35],不难发现Twitter把租赁来的计算资源,大部分用于增加Apache Web Server,而Apache是Twitter整个系统的最前沿的环节。
为什么Twitter很少把租赁来的计算资源,分配给Mongrel Rails Server,MemCached Servers,Varnish HTTP Accelerators等等其它环节?在回答这个问题以前,我们先复习一下前一章“数据流与控制流”的末尾,Twitter从写到读的6个步骤。
这 6个步骤的前2步说到,每个访问Twitter网站的浏览器,都与网站保持长连接。目的是一旦有人发表新的短信,Twitter网站在500ms以内,把新短信push给他的读者。问题是在没有更新的时候,每个长连接占用一个Apache的进程,而这个进程处于空循环。所以,绝大多数Apache进程,在绝大多数时间里,处于空循环,因此占用了大量资源。
事实上,通过Apache Web Servers的流量,虽然只占Twitter总流量的10%-20%,但是Apache却占用了Twitter整个服务器集群的50%的资源[16]。所以,从旁观者角度来看,Twitter将来势必罢黜Apache。但是目前,当Twitter分配计算资源时,迫不得已,只能优先保证Apache的需求。
迫不得已只是一方面的原因,另一方面,也表明Twitter的工程师们,对其系统中的其它环节,太有信心了。
在第四章“抗洪需要隔离”中,我们曾经打过一个比方,“在晚餐高峰时段,餐馆常常客满。对于新来的顾客,餐馆服务员不是拒之门外,而是让这些顾客在休息厅等待”。对于Twitter系统来说,Apache充当的角色就是休息厅。只要休息厅足够大,就能暂时稳住用户,换句行话讲,就是不让用户收到HTTP 503的错误提示。
稳住用户以后,接下去的工作是高效率地提供服务。高效率的服务,体现在Twitter业务流程6个步骤中的后4步。为什么Twitter对这4步这么有信心?
[16] Updating Twitter without service disruptions. (http://gojko.net/2009/03/16/qcon-london-2009-upgrading-twitter-without-service-disruptions/)
[30] Giants and Patriots draws 97.5 million US audience to the Super Bowl. (http://www.reuters.com/article/topNews/idUSN0420266320080204)
[31] Twitter traffic during Super Bowl 2008. (http://blog.twitter.com/2008/02/highlights-from-superbowl-sunday.html)
[32] Joyent provides Twitter free extra capacity during the Super Bowl 2008. (http://blog.twitter.com/2008/01/happy-happy-joyent.html)
[33] Twitter stopped using Joyent's cloud at 10PM, Jan 30, 2008. (http://www.joyent.com/joyeurblog/2008/01/31/twitter-and-joyent-update/)
[34] The hasty divorce for Twitter and Joyent. (http://www.datacenterknowledge.com/archives/2008/01/31/hasty-divorce-for-twitter-joyent/)
[35] The usage of Netcraft by Twitter. (http://toolbar.netcraft.com/site_report?url=http://twitter.com)
鲜花已经成功送出,可通过工具取消
提示:此次送花为此次送花为【有效送花赞扬,涨乐善、声望】。
回国有一阵子了,该交思想汇报了吧?呵呵
不过有些事比较敏感,等待时机成熟再写吧。
鲜花已经成功送出,可通过工具取消
提示:此次送花为此次送花为【有效送花赞扬,涨乐善、声望】。
此种架构可供商榷的地方还很多,估计量级再上去就有问题了。
其实论起互联网海量服务,国内已经非常强悍了,尤以腾讯为首。只是这些公司极为低调,外面看不到什么资料而已。
中国提供了一个广阔的舞台,超大规模的网站在这个舞台上表演。
这个舞台,是世界上绝无仅有的。
QQ就是一个例子,但是不可否认的是,QQ的后台server做得不好。当你打开QQ空间,当你很不耐烦地等待页面打开的时候,我的意思你就明白了。
从朋友那了解到一些资料。
QQ和QQ空间其实是两套东西,由不同的部门负责。
QQ空间的速度确实是经常被人诟病的,但他们也一直在优化,现在确实比以前好多了。在中国的网络环境中,在那个恐怖的量级上,如此复杂的页面,能做到今天这个地步,应该是有很多故事可以讲的。只可惜人家不说。
我刚刚从国内探亲回来,手头有些挤压的事情需要处理,等过段时间静下心来再与邓兄讨论一些细节。
如邓兄所言,cache和queue是twitter两大法宝(在我看来也是很多大型网站的扩展的关键),关于memcache,网上的讨论已经很多,你这个系列中能否详细谈谈twitter queue机制和特点呢?
上周事情较多,忙忙碌碌,一直没有静下心。
下周一定补上Kestrel Queue的问题。
1. twitter的apache 为每个访客创建一个worker process。
创建process的成本是很高的,apache httpd还提供了worker模式可以为每个request创建一个线程,这样能够支持更高的并发。
2. apache把短信和user id转发给mongrel rails之后,处于同步等待状况。
为什么要采用这种方式?这样的话在mongrel回复之前,apache的这个连接所在的进程/线程是不能处理其他请求的,就会成为系统的瓶颈。
在这种架构下,apache如果采用传统的prefork/worker模式,都是不能满足性能需求的,为什么还会这样设计?感觉使用nginx或者mochiweb都是比较成熟的技术,能够更好的解决这个问题。当初设计上有什么特殊的原因吗,请邓兄解释解释,呵呵。
除了erlang开发的yaws,还有erlang的mochiweb,c/c++的nginx以及lightd,都是采用epoll技术能够支持更多的并发连接。就是apache现在也有一个event模块,使用epoll,比prefork/worker性能好多了。