主题:【原创】解剖Twitter 【1】 -- 邓侃
- 共: 💬 68 🌺 272
时常听到“浮躁”这个词,批评现代人不求甚解,缺乏严谨踏实的作风。这种批评有狭隘之嫌。每代人所处的环境不同,面临的问题不同,所以逐渐养成一种风气,去适应新的环境,解决新的问题。
几百年前,人们读长篇小说,看歌剧,听交响乐。到了二十世纪,大家读杂志报纸,看电影电视,听流行歌曲。信息时代,人们上网,读博客,看视频。在这些表象的背后,促成这些风气进化的,是信息的产量与传播速度的激增。面对海量而且迅速更新的信息,人人捧读红楼梦,一唱三咏的局面是难以想象的。取而代之的,是要求信息的篇幅简短,而重点突出。
随着信息爆炸的加剧,微博客网站Twitter横空出世了。用横空出世这个词来形容Twitter的成长,并不夸张。从2006年5月Twitter上线,到2007年12月,一年半的时间里,Twitter用户数从0增长到6.6万。又过了一年,2008年12月,Twitter的用户数达到5百万[1]。
Twitter用户数的急剧攀升,与几次重大事件有关,2007年3月美国SXSW音乐节,2008年11月印度孟买的恐怖事件,2009年1月奥巴马总统就职,2009年6月伊朗选举危机等等。重大事件的报导,特点是读者多,更新快。所以,Twitter网站的成功,先决条件是能够同时给千万用户提供服务,而且提供服务的速度要快。 [2,3,4]
有观点认为,Twitter的业务逻辑简单,所以竞争门槛低。前半句正确,但是后半句有商榷余地。Twitter的竞争力,离不开严谨的系统架构设计。
【1】万事开头易
Twitter的核心业务逻辑,在于Following和Be followed。[5]
进入Twitter个人主页,你会看到你following的那些作者,最近发表的微博客。所谓微博客,就是一则短信,Twitter规定,短信的长度不得超过140个字。短信不仅可以包含普通文字信息,也可以包含URL,指向某个网页,或者照片及视频等等。这就是following的过程。
当你写了一则短信并发表以后,你的followers会立刻在他们的个人主页中看到你写的最新短信。这就是be followed的过程。
实现这个业务流程似乎很容易。
1. 为每一个注册用户订制一个Be-followed的表,主要内容是每一个follower的ID。同时,也订制一个Following的表,主要内容是每一个following作者的ID。
2. 当用户打开自己的个人空间时,Twitter先查阅Following表,找到所有following的作者的ID。然后去数据库读取每一位作者最近写的短信。汇总后按时间顺序显示在用户的个人主页上。
3. 当用户写了一则短信时,Twitter先查阅Be-followed表,找到所有followers的IDs。然后逐个更新那些followers的主页。
如果有follower正在阅读他的Twitter个人主页,主页里暗含的JavaScript会自动每隔几十秒,访问一下Twitter服务器,检查正在看的这个个人主页是否有更新。如果有更新,立刻下载新的主页内容。这样follower就能读到最新发表的短信了。
从作者发表到读者获取,中间的延迟,取决于JavaScript更新的间隔,以及Twitter服务器更新每个follower的主页的时间。
从系统架构上来说,似乎传统的三段论(Three-tier architecture [6]),足够满足这个业务逻辑的需要。事实上,最初的Twitter系统架构,的确就是三段论。
Reference,
[1] Fixing Twitter. (http://www.bookfm.com/courseware/coursewaredetail.html?cid=100777)
[2] Twitter blows up at SXSW conference. (http://gawker.com/tech/next-big-thing/twitter-blows-up-at-sxsw-conference-243634.php)
[3] First Hand Accounts of Terrorist Attacks in India on Twitter and Flickr. (http://www.techcrunch.com/2008/11/26/first-hand-accounts-of-terrorist-attacks-in-india-on-twitter/)
[4] Social Media Takes Center Stage in Iran. (http://www.findingdulcinea.com/news/technology/2009/June/Twitter-on-Iran-a-Go-to-Source-or-Almost-Useless.html)
[5] Twitter的这些那些. (http://www.ccthere.com/article/2363334) (http://www.ccthere.com/article/2369092)
[6] Three tier architecture. (http://en.wikipedia.org/wiki/Multitier_architecture)
本帖一共被 1 帖 引用 (帖内工具实现)
恭喜:你意外获得【通宝】一枚
鲜花已经成功送出,可通过工具取消
提示:此次送花为此次送花为【有效送花赞扬,涨乐善、声望】。
之前的挖坑路线图,说到伸缩性,我就猜到老邓您得拿twitter开侃,哈哈,这个好玩,还会说到twitter和rails社区那些是是非非吧,花催~~~
只谈架构,不谈其它。
关于大型网站架构,只看一两个还不够,要多看,多横向比较。
西电鲁生谈了Flickr,我这里谈谈Twitter,还有那些要谈?Wikipedia,Facebook,eBay,Amazon?
要不大家分分工,每人写一个,这样速度比较快。
这个大题目,要去买沙发了
就拿wikipedia为例,看看他公开说的架构,就吓人一跳
从用户端开始,geoDNS分发请求,lvs作负载均衡,squid作反向代理缓存,lighttpd作静态内容服务器,另外还有memcached作缓存,lucene提供全文索引服务,还不算对mediawiki程序本身玩儿的花样。。。
squid,lighttpd,lucene,都是出了名的易学难精,被狠狠折腾过的人,甘苦自知,就看wikipedia的性能数据(峰值每秒钟3万个 HTTP 请求,每秒钟 3Gbit 流量,350 台 PC 服务器,还是比较老的数据了),用这些看起来大路货的软件,达到如此效果,单说这些玩意儿的配置以及隐藏在背后的logging&profiling手段,就够喝一壶的。
而且从公开的资料看,还有地方可以存疑
比如apache作为应用服务器跑php,如果php用mod模式的话,从我个人的测试结果看,效率不如fcgi的方式跑在lighttpd上面,刻意为LAMP张目?还是...
这得连载多少集阿。。。
好极了,看来解剖Wikipedia这活儿,就交给兄台好了。很显然,兄台已经做了不少准备工作,只欠动笔了。
西电鲁丁目前在做什么?他那篇解剖Flickr架构的文章,写得扎实。这个工作非常有必要继续下去。
等我们把几个著名的大型网站的架构逐一解剖完了以后,不妨找个出版社出个合集。大家以为如何?
Flickr的架构还差1,2篇就可以结尾,还有些细节要考虑。
找人出版是个好主意,邓兄有门路吗?
抛一块Flickr砖,引来无数玉,太值了。
河里搞出版的人甚多,松风就是一个。
这方面需要学习
哪位大侠给我说下keso博客里说的“@username的用法”是指什么,对应于新浪微博的哪个功能?
人需要,就用技术实现。或许有一天,人真的在虚拟世界里不想出来。
Brain to Brian,
Twitter是纽约时报的关注话题了。
【2】三段论
网站的架构设计,传统的做法是三段论。所谓“传统的”,并不等同于“过时的”。大型网站的架构设计,强调的是实用。新潮的设计,固然吸引人,但是技术可能不成熟,风险高。所以,很多大型网站,走的是稳妥的传统的路子。
2006年5月Twitter刚上线的时候,为了简化网站的开发,他们使用了Ruby-On-Rails工具,而Ruby-On-Rails的设计思想,就是三段论。
1. 前段,即表述层(Presentation Tier) 用的工具是Apache Web Server,主要任务是解析HTTP协议,把来自不同用户的,不同类型的请求,分发给逻辑层。
2. 中段,即逻辑层 (Logic Tier)用的工具是Mongrel Rails Server,利用Rails现成的模块,降低开发的工作量。
3. 后段,即数据层 (Data Tier) 用的工具是MySQL 数据库。
先说后段,数据层。
Twitter 的服务,可以概括为两个核心,1. 用户,2. 短信。用户与用户之间的关系,是追与被追的关系,也就是Following和Be followed。对于一个用户来说,他只读自己“追”的那些人写的短信。而他自己写的短信,只有那些“追”自己的人才会读。抓住这两个核心,就不难理解 Twitter的其它功能是如何实现的[7]。
围绕这两个核心,就可以着手设计Data Schema,也就是存放在数据层(Data Tier)中的数据的组织方式。不妨设置三个表[8],
1. 用户表:用户ID,姓名,登录名和密码,状态(在线与否)。
2. 短信表:短信ID,作者ID,正文(定长,140字),时间戳。
3. 用户关系表,记录追与被追的关系:用户ID,他追的用户IDs (Following),追他的用户IDs (Be followed)。
再说中段,逻辑层。
当用户发表一条短信的时候,执行以下五个步骤,
1. 把该短信记录到“短信表” 中去。
2. 从“用户关系表”中取出追他的用户的IDs。
3. 有些追他的用户目前在线,另一些可能离线。在线与否的状态,可以在“用户表”中查到。过滤掉那些离线的用户的IDs。
4. 把那些追他的并且目前在线的用户的IDs,逐个推进一个队列(Queue)中去。
5. 从这个队列中,逐个取出那些追他的并且目前在线的用户的IDs,并且更新这些人的主页,也就是添加最新发表的这条短信。
以上这五个步骤,都由逻辑层(Logic Tier)负责。前三步容易解决,都是简单的数据库操作。最后两步,需要用到一个辅助工具,队列。队列的意义在于,分离了任务的产生与任务的执行。
队列的实现方式有多种,例如Apache Mina[9]就可以用来做队列。但是Twitter团队自己动手实现了一个队列,Kestrel [10,11]。Mina与Kestrel,各自有什么优缺点,似乎还没人做过详细比较。
不管是Kestrel还是Mina,看起来都很复杂。或许有人问,为什么不用简单的数据结构来实现队列,例如动态链表,甚至静态数组?如果逻辑层只在一台服务器上运行,那么对动态链表和静态数组这样的简单的数据结构,稍加改造,的确可以当作队列使用。Kestrel和Mina这些“重量级”的队列,意义在于支持联络多台机器的,分布式的队列。在本系列以后的篇幅中,将会重点介绍。
最后说说前段,表述层。
表述层的主要职能有两个,1. HTTP协议处理器(HTTP Processor),包括拆解接收到的用户请求,以及封装需要发出的结果。2. 分发器(Dispatcher),把接收到的用户请求,分发给逻辑层的机器处理。如果逻辑层只有一台机器,那么分发器无意义。但是如果逻辑层由多台机器组成,什么样的请求,发给逻辑层里面哪一台机器,就大有讲究了。逻辑层里众多机器,可能各自专门负责特定的功能,而在同功能的机器之间,要分摊工作,使负载均衡。
访问Twitter网站的,不仅仅是浏览器,而且还有手机,还有像QQ那样的电脑桌面工具,另外还有各式各样的网站插件,以便把其它网站联系到Twitter.com上来[12]。因此,Twitter的访问者与Twitter网站之间的通讯协议,不一定是HTTP,也存在其它协议。
三段论的Twitter架构,主要是针对HTTP协议的终端。但是对于其它协议的终端,Twitter的架构没有明显地划分成三段,而是把表述层和逻辑层合二为一,在Twitter的文献中,这二合一经常被称为“API”。
综上所述,一个能够完成Twitter基本功能的,简单的架构如Figure 1 所示。或许大家会觉得疑惑,这么出名的网站,架构就这么简单?Yes and No,2006年5月Twitter刚上线的时候,Twitter架构与Figure 1差距不大,不一样的地方在于加了一些简单的缓存(Cache)。即便到了现在,Twitter的架构依然可以清晰地看到Figure 1 的轮廓。
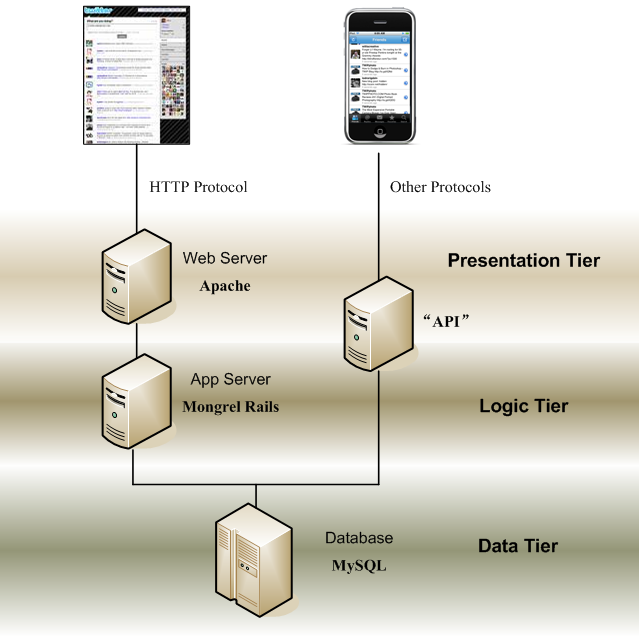
Figure 1. The essential 3-tier of Twitter architecture
Courtesy http://farm3.static.flickr.com/2683/4051785892_e677ae9d33_o.png
Reference,
[7] Tweets中常用的工具 (http://www.ccthere.com/article/2383833)
[8] 构建基于PHP的微博客服务 (http://webservices.ctocio.com.cn/188/9092188.shtml)
[9] Apache Mina Homepage (http://mina.apache.org/)
[10] Kestrel Readme (http://github.com/robey/kestrel)
[11] A Working Guide to Kestrel. (http://github.com/robey/kestrel/blob/master/docs/guide.md)
[12] Alphabetical List of Twitter Services and Applications (http://en.wikipedia.org/wiki/List_of_Twitter_services_and_applications)
恭喜:你意外获得【通宝】一枚
鲜花已经成功送出,可通过工具取消
提示:此次送花为此次送花为【有效送花赞扬,涨乐善、声望】。