- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【半原创】Flickr 网站架构研究(1) -- 西电鲁丁
对于Flickr这样运行几百台甚至上千台服务器,以及网络和存储设备的大型网站来说,有效的监视整个系统各部分的运行状况,及时发现并处理故障和潜在的问题,是保障网站平稳和可持续运营的关键。
以系统监控和网络管理为主要目的的软件通常称之为“网管软件”,商用软件中以IBM Tivoli, HP OpenView,和CA Unicenter TNG为主流,开源社区则以OpenNMS和Nagios为代表,Flickr采用的是Nagios。传统上定义的网络管理有五大功能:故障管理、配置管理、性能管理、安全管理、计费管理。近些年随着”全面管理“概念的引入,这类软件一般更多的自称为“企业基础架构管理软件”。
SNMP即“Simple Network Management Protocol”是目前最常用的网络管理协议,目前几乎所有的网络设备和主流操作系统都实现了对SNMP的支持。它提供了一种从网络上的设备中收集网络管理信息的方法,也为设备向网络管理工作站报告问题和错误提供了一种方法。
SNMP的最初版本1.0只定义了5种报文:Get,GetNext,getResponse,Set,Trap(这也是它称之为“简单”的原因,而事实上SNMP报文的编解码较为复杂。),示意图如下:
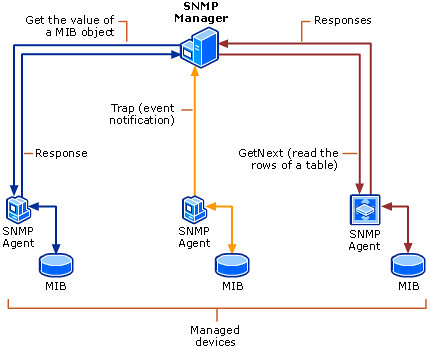
SNMP采用UDP作为传输协议,Get,GetNext,用于NMS Manager(一般即网管主机)以轮询(Polling)的方式向SNMP Agent(一般运行在网络设备或服务器上)发出获取MIB(Management Information Base)节点信息的请求,GetResponse则是SNMP Agent的回应,Set用于写操作(实际中很少使用),这4个报文都通过161端口传输;当SNMP Agent端发现所监控的对象(MIB节点)出现故障,则主动向NMS Manager的162端口发出Trap告警。(详细的SNMP协议介绍不在本文内容之内,有兴趣的话可以另贴讨论)
SNMP的协议特点使得"网管软件"能够及时地被动接收网络上的各种告警(Trap)信息,并根据告警信息的内容和级别触发响应的程序进行处理。例如Nagios提供了超过50个各类插件(plugin)用于监控常用的网络设备,服务器系统资源,后台服务进程和软件等,也可以根据需要自行开发相应的客户化插件用于监控特定的资源和事件。
Flickr将告警分为以下几类:
1)Up/Down,例如定期检查Apache Server和一些后台服务的状态,发现响应失败则自动重起服务进程,并通知管理员(根据级别采用事后邮件或实时短信、寻呼等)。对于一些服务或应用,有必要检查每一个子进程或服务的Up/Down的状态;而对另一些服务和应用,则可能需要“整体”来看,比如,几十台Web Server中的一台故障,一般不需要马上处理,而MySQL Master Server故障,则要马上通知DBA。
2)资源不足,例如硬盘空间或网络带宽不足时邮件提醒管理员考虑购买新的硬盘或增加网络带宽。
3)超过或低于阀值,例如CPU利用率,DISK I/O长时间过高等;或者某台Web Server处理的交易请求突然大幅度降低等。
一开始困难往往在于不知道哪些事件需要告警,哪些则可以忽略。Flickr的经验是先定义尽可能多的事件,然后随着运营的稳定和经验数据的积累再逐步减少。另外,定义完善的告警级别和上报流程也有助于减少不必要的人工和尽快排除故障。
网管软件的功能当然不只是“告警”,性能管理和“趋势”管理也越来越成为“企业基础架构管理”的重要组成部分。不过尽管网管软件可以通过扩展来提供一定程度上的此类功能,但SNMP协议本身的效率并不高,而且当网络达到了一定规模时,主动轮询的方式也限制了它的扩展性和采集大量的数据,一般常见的轮询间隔往往只能限定为10-15分钟甚至更长,这样的采样颗粒度有时很难满足精度和精确分析的要求,因而在大型网络环境下,人们通常更倾向于专门的“数据采集和趋势分析“软件,而这其中的佼佼者就是大名鼎鼎的Ganglia
Ganglia诞生于著名的伯克利大学,最早专用于高性能计算(HPC)环境中的cluster和Grid的监控,经过精心设计的数据结构和算法,使得Ganglia能够以较小的开销同时监视数千台节点。
Ganglia的数据流如下图:
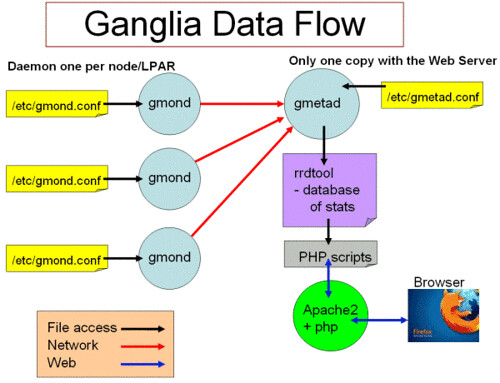
gmond进程,运行在各个节点负责收集数据,并通过multicast或unicast向运行于后台服务端的gmetd进程发送数据,gmetd汇聚数据并存入RRDTool所管理的Round Robin Database.
Round Robin Database是一种特殊的数据库,它对于存储于其中的数据根据时间的远近而保存不同的数据“分辨率”,比如对于较近时间段数据保存每分钟一个采样点,而对于一年以前的数据则只保留每天一个采样点,超过用户指定的期限如几年则自动将过期数据删除。RRD的理论出发点是人们一般较关心近期数据的精确性,而对于长期数据,则只关心大的趋势。RRD的特点使得它能够将数据库的规模限制在一定大小,而不是随着时间的持续而无限增长,这就解决了在相对长的时间内保存大量趋势数据的关键问题,因而在数据采集和趋势分析软件中得到了广泛的应用。
虽然gmond本身可以采集操作系统一级的大量系统信息,如CPU,内存,硬盘和网络I/O等,但光有这些信息是远远不够的,对于一个网站来说,更重要的是了解这些系统信息所代表或对应的业务信息的含义,比如CPU利用率40%时,网站的平均响应时间是多少,网站同时能够支持的并发用户是多少。这些信息更多的来自于应用或基础构件(如MySQL,Web Server,Memcache,Squid等),而Ganglia提供的另一个程序gmetric,则可以通过cron定期调用script的方式来采集这些客户化的应用层数据并发送到gmetd。例如下面的代码分别用于获取disk util和memcache的命中率,
#!/bin/sh
/usr/bin/iostat -x 4 2 sda | grep -v ^$ | tail -4 > /tmp/
disk-io.tmp
UTIL=`grep sda /tmp/disk-io.tmp | awk '{print $14}'`
/usr/bin/gmetric -t uint16 -n disk-util -v$UTIL -u '%'
。。。。。。
/usr/bin/gmetric -t uint32 -n memcachced_hitratio -v$HITRATIO -u ’%’
Apache,MySQL,Memcache,Squid等一般都可以某种方式提供一定程度上的实时统计信息,通过对这些数据的定期采样(如每分钟),可以很清楚的显示整个系统近乎实时的运营情况,找出各个数据相互之间的关系及其规律,并以此作为容量规划的依据。下面是Flickr的运营主管在一次会议上展示的Flickr的Ganglia系统。
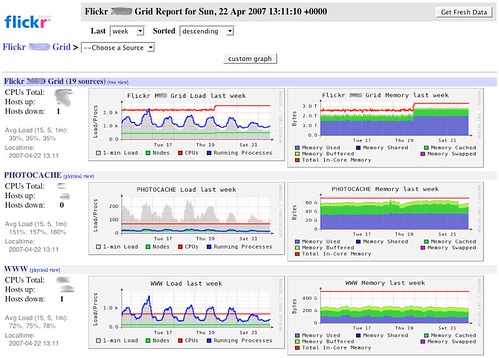
除了这些子系统本身提供的一些实时的统计数据外,Web Server的Access Log是另一个重要的统计和性能数据来源。一行典型的Access Log包括:用户的IP地址,访问时间,执行时间(time-taken),网页的URL,HTTP的响应码,数据包大小等。通过对这些Log的分析,我们可以得到很多有用的信息。一个最常见的困难是,如何按照时间顺序汇总几十台甚至数百台Web Server的Log。传统的手工COPY和处理不仅费时,而且COPY的时候占用网络资源较大。所幸的是Spread Toolkit帮我们解决了这个问题,采用Spread toolkit进行开发,我们可以将多台Web Server的Log以multicast的方式实时传输到一台或几台(用于Fail-over)集中的Log Server。特别的对于Apache,可以直接下载和使用一个基于Spread的现成模块mod_log_spread,采用mod_log_spread,Apache避免了本地Log的读写,据说可以提高运行效率20-30%。 对于Log的分析,网上虽然有很多软件,如Report Magic等,但这些软件并不懂你的应用,只能做一些基本的分析,Flickr对于这些Log进行了基于应用的分析和处理,并将结果也导入Ganglia。
Access Log的分析是基于Web页面的,Flickr的技术团队认为这还不足够,因而进一步对于页面的每个task进行计数,比如总共有多少访问是memcache的,多少是直接调用数据库的。最常见的想法是利用数据库,每次访问则更新数据库的记录,这对于每秒访问量成千上万的繁忙网站来说基本上是不可行的,因为连接和更新数据库的开销太大。Flickr使用的是UDP,PHP的相关代码如下:
$fp = fsockopen("udp://$server", $port, $errno, $errstr);
if ($fp){
fwrite($fp, "$value\n");
fclose($fp);
}
$value即是所要计数的counter的名称。一个后台的Perl进程每收到一个counter,就在相应的counter的计数上加1,并定期存入RRD。
计数之外,Flickr还对一些任务计时。一些后台程序定期执行这些特定任务并记录这些任务所花费的时间。
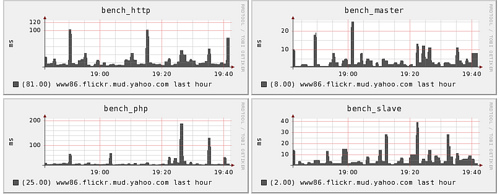
由于环境的影响,每次计时可能都会不同,获得标准偏差比简单的取平均值更要有意义。例如下图:
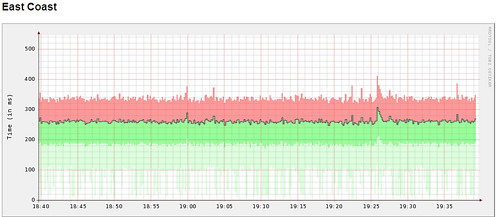
此项示例任务平均时间为250ms,75%的任务时间大约340ms,25%的任务在 190ms以内,最下面的浅绿线则是剩下的25%。
Flickr公开了这段代码,有兴趣的可以在这里下载。
最后简单讲一下Flickr如何确定系统的“边界”,即在可接受的性能条件下的最大负载。Flickr并不太看重在测试系统所作的benchmark或者是压力测试。在大多数情况下,测试环境很难完全100%的模拟真实的投产环境,即使软硬件环境完全一致,并完全复制投产系统的数据,因为大量用户的行为是无法完全模拟的。虽然有一些Log replay软件(如Httperf,Siege)可以根据Web Access Log作一定程度的模拟,但一般来说Access Log不包括HTTP POST的请求参数,无法replay,而且replay软件也无法模拟由于地理位置和网络不同而造成的网络迟延等问题。Flickr采用的是“controlled production load testing",即直接在投产系统测试来取得特定配置下Server的最大负载。这其中的关键是Load Balancer,通过调节Load Balancer的负载分配,逐渐增加指定Server的访问量,直到达到临界值为止。
推荐一本书《The Art of Capacity Planning》,这是Flickr运营主管写的一本关于大型网站容量规划的书,书中没有什么高深的数学公式,完全从实战的角度出发,值得一看。
祝大家新年快乐,虎年吉祥。
现在我一下子想不起来要干什么了,但是有个想法也许和这个更新有关系。是早上在上班的路上想的,所以有点记不清了。
应该是记录某种状态,然后再作分析有一定的关系。当时也是有考虑到数据库链接和更新的开销。不过,我在想,比如说我设定一个表,表的名字和日期关联,没有index,只往里面写,不读,然后过一天后换一个表,并将前一天的表拿出来作分析,那样是不是不会有太大的拖累?
不知道为什么用UDP速度会快一些?
多谢好文,要慢慢参考。
另外,关键词用逗号分隔。
也祝新年快乐,虎年吉祥。
数据库的好处是查询方便,而且安全可靠。其实还是要看流量,比如Flickr一秒中有4万笔照片访问,如果都记数据库的话,不算connection的开销,那么至少要4万笔更新或者插入,这个开销是相当可观的。
UDP是“无连接传输”,即有数据立即传输,不需要象TCP那样先建立连接,而且没有TCP那样的数据流控制,如ACK,“三次握手”,checksum等,因而不能保证100%的可靠传输,但也正是因为没有这些TCP的overhead,因而对系统的资源消耗较少,在数据报文较大时,网络情况较好(比如LAN)时,效率比TCP要高。
在数据报文较小的情况下,也可以考虑试试TCP的Nagle's algorithm,即通过设置TCP_NODELAY的系统参数,可以缓存多个TCP数据包而后一起发送,这时TCP反而可能会比UDP要快,具体环境下最好要测一下才能知道。
以Flickr的情况,TCP不见得比UDP慢,但系统开销肯定要大一些了。
谢谢提示,已修改了关键词。
pinax自己的定位是"Pinax is an open-source platform built on the Django Web Framework.",个人感觉是一个快速开发网站的“应用框架”,而我主要的兴趣和强项是“系统架构”,对于应用层的东西没有太多的研究,不敢乱讲。 不过你若是发原创帖介绍pinax的话,我倒是可以趁机学习学习。
不过你若是发原创帖介绍pinax的话,我倒是可以趁机学习学习。 。
。
Flickr的应用主体开发于2005年,是最早的一批web2.0网站之一,功能相对是比较单一的,研究它的目的,主要是从大型网站系统架构的“可扩展性”出发的;如果只考虑应用层的框架,功能涵盖,模块设计和可重用性,通用性,易用性等方面来讲,可能比不上pinax。但两者的设计目标不同,这样的比较是否有意义?另一方面,pinax也许较适合刚起步的中小网站,可以快速建站,但网站达到一定规模后是否还适用,似乎尚存疑问。
下一个系列,我会在facebook和amazon之间选一个,目前正在收集资料中。
阅读了Flickr网站架构研究前三节,把自己对数据库使用的理解总结一下。这方面没有啥实际经验,总结得也很浅,有什么问题大家多多拍砖。
数据库使用的总原则是在不影响数据库其他方面性能(如数据一致性)的前提下,尽可能提高数据库服务器集群的响应能力,应对更大的访问量。
由于每台服务器的响应能力是相对固定的,因此基本方法是通过增加服务器数量来应对高并发。
架设服务器集群有两个大致的思路。一个是以数据库服务器为单位,通过增加保存相同数据的服务器的数量来分摊压力,不考虑服务器上数据的性质。另一个是以数据为单位,通过分拆数据,在不同服务器上保存不同用途的数据来分摊压力。第一种思路对应master-master、master-slave这样的方案。第二种思路比较灵活,需要根据业务特点来选择拆分方法。拆分完毕后可以再利用第一种思路增加每个数据节点的响应能力。
数据拆分从Flickr的经验看有这么几种:
1.读、写拆分。一般来说,读的数量远大于写,因此可以通过增加备份数据库,分担读请求。
2.根据业务分拆数据。例如Flickr中有专门保存用户主键和shard信息的数据库,有用户数据和照片元信息的数据库。
3.根据用户拆分数据。同一用户的数据一般集中在一处,但不同用户的数据可以分别放在不同的机器上。这样通过增加机器数就可以应对更大用户量的访问。
数据拆分比较灵活,和业务特点关系密切,需要根据实际情况来设计。
还有一些和数据库应用相关的内容这里没有提,比如cache的应用,通过异步操作来降低数据库的压力等,都和数据库的设计有密切关系。
暂时就想到这么多啦
对,pinax是应用层的,我是初学者,对架构的概念理解很浅,因为pinax/django看上去简单些,所以才从这里入手学习。因为脑子里只有这么一个模型,所以才将Flickr与pinax去比较,倒不是两者有什么值得比较的地方。看了您的文章后,我感觉已经入门了,呵呵。
现在只能看到主页的文章,2次链接都打不开,只能借贵宝地求助
花谢