主题:【原创】wikipedia架构学习笔记(一)他们的骄傲 -- 羽羊
- 共: 💬 62 🌺 262
家园 【原创】wikipedia架构学习笔记(一)他们的骄傲 Wikipedia架构学习笔记
wikipedia毫无疑问是个超大规模的网站,在软件的使用、配置、管理方面亮点无数,而且wikipedia开放的态度对于后来者学习他们的优秀经验非常有帮助,在几个项目中,都多多少少从wikipedia获益,于是把学习的点点滴滴整理一下、记录下来,最近俗务繁多,也不知道什么时候能填完,小羊一定尽快。因为水平有限,所以本文一定挂一漏万,而且错漏之处一定不少,还请各位指正。
一、wikipedia的骄傲
根据wikipedia自己的说法:
Since its creation in 2001,Wikipedia has grown rapidly into one of the largest reference web sites,
attracting around 65 million visitors monthly as of 2009.
There are more than 75,000 active contributors working on more than 14,000,000 articles in more than 260 languages.
As of today, there are 3,060,942 articles in English.
Every day, hundreds of thousands of visitors from around the world collectively make tens of thousands of edits and create thousands of new articles to augment the knowledge held by the Wikipedia encyclopedia
技术数据,根据Mark Bergsma的pdf:
30 000 HTTP requests/s during peak-time
3 Gbit/s of data traffic
3 data centers: Tampa, Amsterdam, Seoul
350 servers, ranging between 1x P4 to 2x Xeon Quad-
Core, 0.5 - 16 GB of memory
...managed by ~ 6 people
现在的最新数据
(发文前,小羊很八卦的一台台数了一下
 )服务器357台在线,而且排名从Mark Bergsma作报告时的第10名上升到了第六名
)服务器357台在线,而且排名从Mark Bergsma作报告时的第10名上升到了第六名实时性能数据
实时访问数据
2009年4月5日的架构图(写实风格的,能数出server数量。。。
 看到晕倒。。。)
看到晕倒。。。)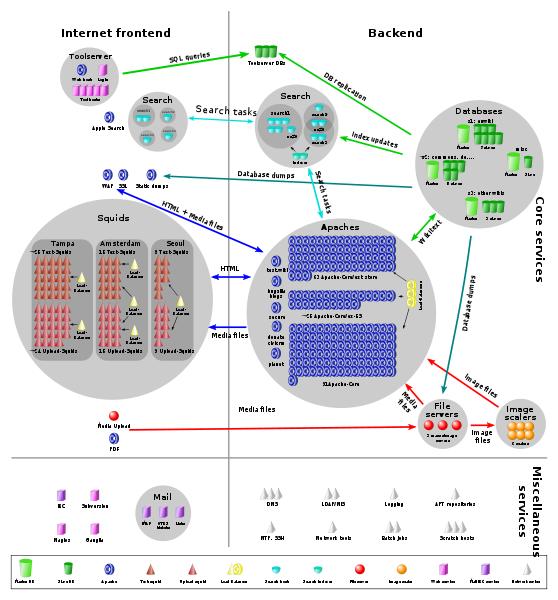 外链图片需谨慎,可能会被源头改
外链图片需谨慎,可能会被源头改花了多少钱?
wikimedia基金会的08-09财年报告,懂财务的自己看吧
一个致力于知识存储、共享和传播的网站
一个致力于知识存储、共享和传播、达到如此规模的网站
他们有充分的理由骄傲。
本帖一共被 1 帖 引用 (帖内工具实现)家园 羊倌,俺谈点俺的心得。 你的这个,西电鲁丁的那个,还有邓侃的那个俺都读了,要说俺看后记住了什么 ------ NOTHING。你说俺这人是不是愚笨了些?

没记住东西不等于没有印象,哪怕是个错误的印象。
这个印象就是这些"大集群"的架构师也就一民工包工头的水平,天天的任务就是头疼医头,脚疼医脚。什么地方出问题(就是鬼子喜欢说的BOTTLE NECK)了,然后就在那里放个性能监测器,把那个“瓶颈”进行动作分解(1,2,3....7.8)。如果3这一步最费资源,能不能把3独立出来用单独的服务器运行,更进一步能不能用一组服务器运行,如何在这一组服务器内进行3的“负载分配”。如此往复,天长日久,于是他们的“功力”见长。
见笑咯见笑咯,俺陪兄弟玩一会。
不过你那个08-09财年报告很好,俺写financial projection的时候从里面推测了好几个数据。谢了。
家园 【原创】cache,没比有好,少比多好(上) 现在,memcached几乎成了网站标配的东西,无论什么网站,一旦性能出了问题,首先想的几乎都是“我是不是要上个memcached?”
现在玩儿php的多,flickr,wikipedia都是基于php的,咱们就拿php说事儿,这种cache偏执症,小羊接触过十个用php的其中就有八个,而且这八个当中还真没有多少实际在项目当中用过cache,反倒是玩儿java或者python,ruby这些动态语言的哥们儿,cache对于他们几乎就是常态,用的多了,倒对于cache有不同的看法,那就是——没比有好,少比多好。
先前有朋友的回帖中,已经看出了性能报告显示的问题,我们延展开来先吹吹cache的冷风。
关于memcached,有两个通常的误解,第一,应用cache是很方便的,第二,无论怎么说,cache总是比数据库要快,我们就从这两个方面说起。
一、memcached不是数据库,它和数据库在使用上的区别就好像BASIC的文件操作和C语言的指针,memcached实际上是一个大的内存hash,所有的读写都是在操作key=>value对,换句话说,需要得到一个value,必须明确知道其对应的key,一个习惯了select,insert,update,delete的程序员在第一眼面对memcached的时候都会非常不适应。毫无疑问,应用memcached会带来代码层面的改动,所以,混乱的代码和对于应用memcached不充分的前期准备都会使这项改动代码的工作成为噩梦。就算是在访问层面跨过了这一关,后头还有一个缓存和数据库同步的问题在等着你,“脏数据”,这个通常被RDBMS处理掉的问题,现在需要程序员自己操作了。
另外,小羊接触的很多对memcached满怀憧憬的哥们儿都有一个普遍的误解,那就是几乎所有memcached介绍文章都会提到的的“分布式”,好像这下子程序可以无限制的水平扩展下去了,实际上,memcached本身恰恰是不具备分布式能力的,甚至多个memcached多个节点之间无通讯还是它的一个卖点。所谓分布,是由memcached的接口函数实现的,多了这么一个接口程序,又是一个复杂度的上升,而且还有函数库本身效率出现问题的风险。
二、应用cache一定很快么?先考虑读取数据的问题,对于简单的查询,memcached的操作速度通常和经过良好优化的数据库一样快,select a from b where x=y 的操作数据库花不了1ms的时间,memcached也快不到哪儿去。如果碰到缓存没有命中,那么仍然需要访问数据库,说不定还要把访问结果写入缓存,那么花费的代价则是数据库的至少两倍。
假设缓存总是命中,那么从速度上面看,查询越是复杂,memcached的优势越大,因为我们会在memcached中仅仅存放查询结果,而数据库则要稀里哗啦把N个表折腾一下。但是慢着,我们好像在讨论复杂查询结果放入缓存的问题,那么首先看看所谓的“复杂查询”,如果需要把一个“复杂查询”的结果放入缓存,那么意味着这个复杂查询的访问频率相当的高,否则我们只能得到低下的“缓存命中率”了,考虑到应用memcached带来的代码、架构以及维护的复杂度上升,低下的“缓存命中率”几乎等于得不偿失。如果缓存命中率很高,您的应用需要频繁的使用这么复杂的查询,那么也许首先要做的不是考虑memcached,而是检讨一下整个系统包括数据库结构的设计了。假如在信息版回帖,西西河的程序需要先要动用一个关联N张表的复杂查询,判断一下经验、声望、乐善、是否认证...这样...绝大多数不明真相的河友面对一页页500错误一定义愤填膺,那样会让GFW蒙受不白之冤,亲者痛仇者快阿~~最重要的是:如果这样的代码是小羊写的,那么老铁一定不给工钱,小羊只好过年的时候去爬脚手架了。
除了读数据,还有写数据的问题,通常,为解决缓存和数据库同步问题,可以有两种方法,第一种是从数据库读出数据后,写入缓存,以后直接读缓存,这是一个常见的说法,长野雅广、前坂徹在广为传播的《memcachedを知り尽くす》一文中开篇说的就是它。第二种方法是在写数据的时候同时写入缓存,读的时候直接读缓存。无论哪种方法,如果数据经常被访问,那么我们两次的辛苦也就罢了,如果访问率很低。。。嘿嘿,反正内存便宜,希望大家都可以不用关注成本问题而且收入和代码行数挂钩。
罗罗嗦嗦说了这么多,memcached还真是麻烦阿。没错,这就是开篇所说的——在性能没有问题的情况下,cache,没比有好,少比多好。
如果读到这儿,您认为memcached能存在到今天都是错误的话,那么,小羊首先要道歉,这不是小羊的本意。memcachd其实真的是好东西,只不过,使用的难度很大,也很考程序员和架构师的功力,明确了这一点,在回头看看wikipedia,才会理解wikipeida在使用memcached上的精要之处。
喝水
元宝推荐:铁手,家园 楼主有点标题党,补充一下 使用cache当然需要有前提条件,当符合条件时,cache就是有比没好,多比少好了。
例如文中提到的memcached实际是个write through的cache,当读访问远远多于写访问,并且读的内容比较集中时,用它可以大大降低数据库压力。
另外memcached的访问速度还是很快的,如果说db的速度通常在1ms的话,mc的速度基本上是在50us的水平。
除了访问速度快,mc还有一个优点是性能上限高。在现在的主流配置下,mc的访问性能可以达到100000qps以上。这对于web之类的应用是比较关键的。因为对于这些应用,所谓“性能不是问题”通常都是暂时的,可能中午不是问题,到了晚上访问量翻倍,db性能就是问题了。而如果有cache的保护,情况可能会好的多。
家园 哪有这么计算时间的? memcached的主要目的是为了缓解数据库的压力。
家园 memcached没用过 我是做java的,各种数据库持久层的cache倒是常用,用与不用确实相差很多
有时为了比较好的用户体验和降低数据库的IO操作也常用cache,将各种常用的数据放入cache中,实现数据库只写,cache只读,cache定时与数据库进行同步。
不过比较复杂的问题是cache做分布不大好做,碰到前端应用做了集群cache再去做集群就不大好扩充了。。
现在我更多的是使用内存数据库H2,性能比MYSQL的内存数据库好,还不要钱,是个好东西
家园 类似memcached的缓存java里面很常见 在我的理解和经验里面,常用的场景是对象缓存。java下面的开发的一个潮流和趋势是数据的对象化,由框架实现对象和数据库表的映射关系(当然直接用sql从表读取数据也是常见)。这时常见的性能瓶颈都会出现在从表读取数据映射到对象上以及对象保持到数据库的时候。
通过map方式缓存已读取出来的对象,对于会频繁读而少写的对象,缓存此时会起到很大的作用。可以看到memcached的缓存和java的这个缓存模式基本是一致的。
家园 对这个memcached有兴趣 之前找过一点东西看,看的云里雾里,不知道它到底好在哪里,到底不好在哪里。
按照我的理解,它的主要目的,应该是为了减轻数据库的负担。主要的方式,就是把后台数据库的内容搬一些到前台来,如果前台能够满足需求,后台的操作就会大幅度减少。数据库的操作所对应的负荷,可能还不只是数据库设计的问题,更主要是因为读写操作一多,并发的问题就比较突出一些。
memcached 至少可以大幅减少读操作。可是如果这样的话,就有人建议用数据库的 replicate 来分布读操作。
如果是用 php ,那么用 apc 是不是和 memcached 本质上可以达到一样的效果?
和那些 reverse proxy 又有什么本质上的区别?还是只是缓存的级别不同,一个是部分内容,一个是整个网页?
家园 讨论一下 先说个题外话,mysql的创始人在离开sun之后又新搞了个数据库,叫啥名字忘记了。这个数据库里面没有query cache,据他自己说法是这部分交给memcached了。
这可以说明,memcached很像db的query cache,但是又有些优势。是什么优势呢?我想主要是:
1. query cache是以sql做key的,非常不灵活,提高命中率比较难
2. query cache不够大。mysql的query cache缺省是16M,太小了。
3. memcached在应用和部署上都更灵活,更适合高并发访问。
由于memcachd是key->value的存储模式,跟db的sql有很大的不同,所以在应用的时候,最好是用key/value模式重构数据模型。这样memcached就不是简单的存储sql查询的结果,从而有效提高存储和使用的效率。
memcached 至少可以大幅减少读操作。可是如果这样的话,就有人建议用数据库的 replicate 来分布读操作。当使用replicate来分布读操作时,写操作一般都是在master上完成。这种模式下还是需要应用程序进行修改,严格区分读写请求。实际跟使用memcached的工作量差不多。而memcached相比从数据库而言要轻量多了。
和那些 reverse proxy 又有什么本质上的区别?还是只是缓存的级别不同,一个是部分内容,一个是整个网页?这是一个不同之处。并且reverse proxy不一定是完全基于内存的,还是有可能发生io。本质不同应该是memcached可以存的东西远远不止网页,事实上可以是任何东西。
通宝推:铁手,

){kind=link}