- 近期网站停站换新具体说明
- 按以上说明时间,延期一周至网站时间26-27左右。具体实施前两天会在此提前通知具体实施时间
主题:【半原创】Flickr 网站架构研究(1) -- 西电鲁丁
也许有人不相信,不过Flickr确实是从一台服务器起步的,即Apache/PHP和MySQL是运行在同一台服务器上的,很快MySQL服务器就独立了出来,成了双服务器架构。随着用户和访问量的快速增长,MySQL数据库开始承受越来越大的压力,成为应用瓶颈,导致网站应用响应速度变慢,MySQL的扩展问题就摆在了Flickr的技术团队面前。
不幸的是,在当时,他们的选择并不多。一般来说,数据库的扩展无外是两条路,Scale-Up和Scale-Out,所谓Scale-Up,简单的说就是在同一台机器内增加CPU,内存等硬件来增加数据库系统的处理能力,一般不需要修改应用程序;而Scale-Out,就是我们通常所说的数据库集群方式,即通过增加运行数据库服务器的数量来提高系统整体的能力,而应用程序则一般需要进行相应的修改。在常见的商业数据库中,Oracle具有很强的Scale-Up的能力,很早就能够支持几十个甚至数百个CPU,运行大型关键业务应用;而微软的SQL SERVER,早期受Wintel架构所限,以Scale-Out著称,但自从几年前突破了Wintel体系架构8路CPU的的限制,Scale-Up的能力一路突飞猛进,最近更是发布了SQL 2008在Windows 2008 R2版运行256个CPU核心(core)的测试结果,开始挑战Oracle的高端市场。而MySQL,直到今年4月,在最终采纳了GOOGLE公司贡献的SMP性能增强的代码后,发布了MySQL5.4后,才开始支持16路CPU的X86系统和64路CPU的CMT系统(基于Sun UltraSPARC 的系统)。
从另一方面来说,Scale-Up受软硬件体系的限制,不可能无限增加CPU和内存,相反Scale-Out却是可以"几乎"无限的扩展,以Google为例,2006年Google一共有超过45万台服务器(谁能告诉我现在他们有多少?!);而且大型SMP服务器的价格远远超过普通的双路服务器,对于很多刚刚起步或是业务增长很难预测的网站来说,不可能也没必要一次性投资购买大型的硬件设备,因而虽然Scale-Out会随着服务器数量的增多而带来管理,部署和维护的成本急剧上升,但确是大多数大型网站当然也包括Flickr的唯一选择。
经过统计,Flickr的技术人员发现,查询即SELECT语句的数量要远远大于添加,更新和
删除的数量,比例达到了大约13:1甚至更多,所以他们采用了“Master-Slave”的复制模式,即所有的“写”操作都在发生在“Master",然后”异步“复制到一台或多台“Slave"上,而所有的”读“操作都转到”Slave"上运行,这样随着“读”交易量的增加,只需增加Slave服务器就可以了。
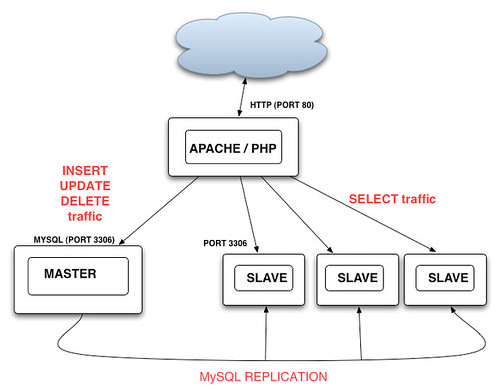
让我们来看一下应用系统应该如何修改来适应这样的架构,除了”读/写“分离外,对于”读“操作最基本的要求是:1)应用程序能够在多个”Slave“上进行负载均分;2)当一个或多个”slave"出现故障时,应用程序能自动尝试下一个“slave”,如果全部“Slave"失效,则返回错误。Flickr曾经考虑过的方案是在Web应用和”Slave“群之间加入一个硬件或软件的”Load Balancer“,如下图
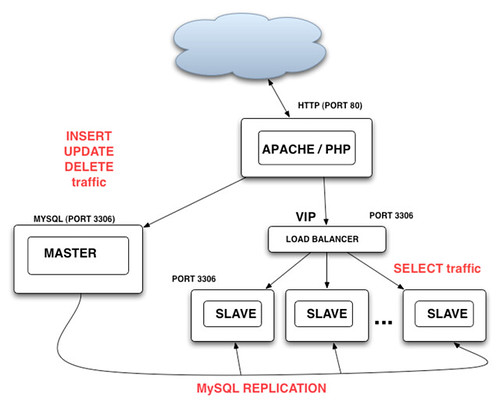
这样的好处是应用所需的改动最小,因为对于应用来说,所有的读操作都是通过一个虚拟的Slave来进行,添加和删除“Slave"服务器对应用透明,Load Balancer 实现对各个Slave服务器状态的监控并将出现故障的Slave从可用节点列表里删除,并可以实现一些复杂的负载分担策略,比如新买的服务器处理能力要高过Slave群中其他的老机器,那么我们可以给这个机器多分配一些负载以最有效的利用资源。一个简单的利用Apache proxy_balancer_module的例子如下:
。。。。。。。。。。。。。。
LoadModule proxy_module modules/mod_proxy.so
LoadModule proxy_balancer_module modules/mod_proxy_balancer.so
LoadModule proxy_http_module modules/mod_proxy_http.so
。。。。。。。。。。。。。。。。。。。。
<Proxy balancer://mycluster>
BalancerMember "http://slave1:8008/App" loadfactor=4
BalancerMember "http://slave2:8008/App" loadfactor=3
BalancerMember "http://slave3:8008/App" loadfactor=3
....................
///slave load ratio 4:3:3.
最终,Flickr采用了一种非常“轻量”但有效的“简易”PHP实现,基本的代码只有10几行,
function db_connect($hosts, $user, $pass){
shuffle($hosts); //shuffle()是PHP函数,作用是将数组中每个元素的顺序随机打乱。
foreach($hosts as $host){
debug("Trying to connect to $host...");
$dbh = @mysql_connect($host, $user, $pass, 1);
if ($dbh){
debug("Connected to $host!");
return $dbh;
}
debug("Failed to connect to $host!");
}
debug("Failed to connect to all hosts in list - giving up!");
return 0;
}
在上述代码中,如果需要对特定的Slave赋予更高的负载,只要在$hosts中多出现一次或多次就可以了。这段代码只要稍稍改进,就可以实现更复杂的功能,如当connect失败时自动将host从hosts列表中去除等。
“Master”-"Slave"模式的缺点是它并没有对于“写'操作提供扩展能力,而且存在单点故障,即一旦Master故障,整个网站将丧失“更新”的能力。解决的办法采用“Master"-"Master"模式,即两台服务器互为”Master“-"Slave",这样不仅”读/写“能力扩展了一倍,而且有效避免了”单点故障“,结合已有的“Master"-"Slave",整个数据库的架构就变成了下面的”双树“结构,
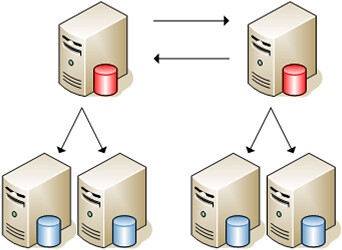
“双树”架构并没有支撑太久的时间,大概6个月后,随着用户的激增,系统再一次达到了极限,不仅”写”操作成为了瓶颈,而且“异步复制"也由于”Slave“服务器过于繁忙而出现了严重的滞后而造成读数据的不一致。那么,能不能在现有架构加以解决,比如说增加新的”Master“服务器和考虑采用”同步复制“呢?答案是否定的,在Master超过两台的设置中,只能采用”闭环链“的方式进行复制,在大数据量的生产环境中,很容易造成在任意时刻没有一个Master或Slave节点是具有全部最新数据的(有点类似于”人一次也不能踏进同一条河“? ),这样很难保障数据的一致性,而且一旦其中一个Master出现故障,将中断整个复制链;而对于”同步复制“,当然这是消除”复制滞后“的最好办法,不过在当时MySQL的同步复制还远没有成熟到可以运用在投产环境中。
),这样很难保障数据的一致性,而且一旦其中一个Master出现故障,将中断整个复制链;而对于”同步复制“,当然这是消除”复制滞后“的最好办法,不过在当时MySQL的同步复制还远没有成熟到可以运用在投产环境中。
Flickr网站的架构,需要一次大的变化来解决长期持续扩展的问题。
- 相关回复 上下关系8
🙂谢谢邓兄参与讨论,花谢! 3 西电鲁丁 字424 2009-08-26 07:02:25
🙂好文 1 张家兄弟 字52 2009-08-17 09:59:36
🙂花谢。 西电鲁丁 字0 2009-08-17 21:13:19
🙂【半原创】Flickr 网站架构研究(2)

🙂【原创】Flickr 网站架构研究(3) 41 西电鲁丁 字7712 2009-08-23 11:53:31
🙂《Flickr网站架构研究》读书笔记 1 chriswang 字1327 2010-03-01 07:03:40
🙂【原创】Flickr 网站架构研究(4) 19 西电鲁丁 字4650 2009-09-06 01:41:51
🙂深入浅出,写得真好,一个小疑问。 1 邓侃 字1023 2009-09-20 20:07:11